
.png)


1. It’s Gemma, Not Gemini
You probably saw “Gemini 4” trending on X. What Google released is Gemma 4, the open-weights sibling of the Gemini family. For computer vision engineers, the open model might matter more than the proprietary one.
Here is why. Gemma 4 ships with Apache 2.0 licensing (a first for the Gemma line), native bounding box output in its response format, configurable image token budgets, and an edge variant that runs on a Raspberry Pi 5 at 7.6 tokens per second. All four model sizes accept images and video as input. The smallest fits in under 1.5 GB of RAM.
This post covers what shipped, how the architecture works for vision tasks, benchmark numbers worth caring about, edge deployment specifics, and an honest look at where Gemma 4 sits against Qwen 3.5 and Llama 4 Scout. If you have worked with Google’s previous vision models like PaliGemma, Gemma 4 represents a major step forward in what open-weights multimodal models can do on device.
2. What Shipped: The Gemma 4 Model Family
Google released four Gemma 4 variants on April 2, 2026. The 31B is the only fully dense model (all 30.7B parameters active per forward pass). The 26B uses Mixture-of-Experts (MoE) routing, activating 8 of 128 experts per token. The two smaller models, E2B and E4B, use Per-Layer Embeddings (PLE) to reduce active computation: they carry more total parameters than they activate per token, though through a different mechanism than traditional MoE routing. All four are multimodal from the ground up, accepting text, images, and video. The two smallest models also accept audio.
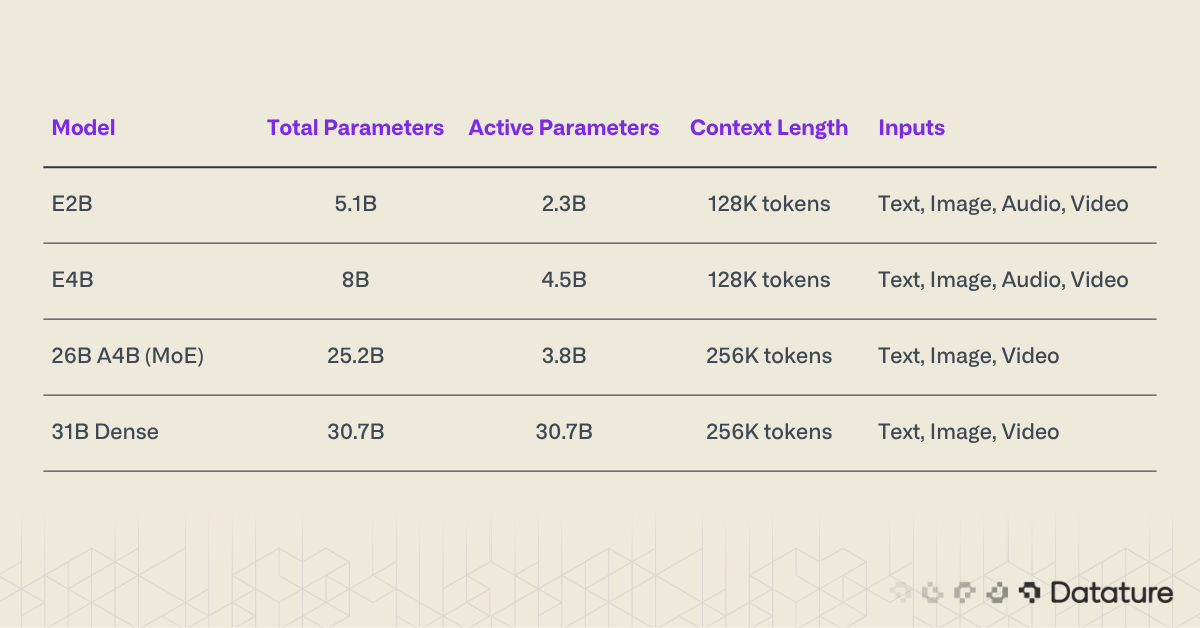
A few things stand out in this lineup. The 26B MoE model activates only 3.8B parameters per token, routing through 8 out of 128 total experts. That means its inference cost is closer to a 4B model than a 25B model, despite carrying 25.2B total parameters. The E2B is the edge play: 2.3B effective parameters, quad-modal input, and a memory footprint under 1.5 GB.
All four models use decoder-only transformer architectures. The two larger models get 256K context windows. The two smaller ones get 128K. No model is text-only; every variant processes images natively.
.png)
Apache 2.0: Why the License Change Matters
Previous Gemma releases shipped with a custom “Gemma Terms of Use” license that placed restrictions on commercial deployment, redistribution, and derivative works. That license created friction for teams building products on top of Gemma models. Apache 2.0 removes all of it. You can fine-tune Gemma 4, deploy it commercially, redistribute modified weights, and build closed-source products on top of it with no usage restrictions.
This puts Gemma 4 on equal legal footing with Llama 4 (which uses the Llama 4 Community License, permissive but with monthly active user thresholds) and Qwen 3.5 (Apache 2.0). For engineering teams choosing between open-weights vision models, licensing is no longer a differentiator. The decision comes down to capability, efficiency, and deployment fit.
3. Architecture: What Matters for Vision Tasks
Gemma 4 is a decoder-only transformer. Nothing exotic on that front. The interesting design decisions sit in three areas: the hybrid attention mechanism, the vision encoder, and configurable image token budgets. Each one directly affects how well the model performs on computer vision workloads.
Hybrid Attention: Sliding Window + Global
Gemma 4 alternates between two types of attention layers. Local sliding-window layers attend to a fixed window of 512 or 1024 tokens. Global full-context layers attend to every token in the sequence. This hybrid approach reduces the memory footprint compared to full attention at every layer while keeping the model’s ability to reason about long-range dependencies.
For vision tasks, this matters when processing multiple images or long video sequences. A 60-second video at 1 fps generates 60 frames. With high token budgets per frame, that adds up fast. Sliding-window layers handle most of the local pattern recognition (edges, textures, spatial relationships within a single frame) while global layers handle cross-frame reasoning.
Per-Layer Embeddings (PLE)
Standard transformers compute one embedding per token at the input layer and pass it through the network. Gemma 4 introduces Per-Layer Embeddings: a secondary embedding signal injected into every decoder layer. This gives each layer its own positional and semantic anchor rather than relying on residual connections to propagate the original embedding upward through dozens of layers.
The practical effect is better gradient flow and more stable training, especially in the deeper layers of the 31B model. For fine-tuning on vision tasks, PLE may help maintain spatial awareness in later layers that would otherwise drift toward abstract language representations.
Shared KV Cache
The last N layers of each Gemma 4 model reuse key-value tensors from the previous layer instead of computing fresh KV pairs. This cuts KV cache memory without discarding the attention pattern entirely. During inference, KV cache size is one of the primary bottlenecks for running large models on limited hardware. Sharing the cache across adjacent layers is a practical engineering trade-off: small accuracy cost, measurable memory savings.
.png)
Vision Encoder: Variable Resolution and Token Budgets
Gemma 4’s vision encoder uses learned 2D positional embeddings combined with multidimensional RoPE (Rotary Position Embedding). The key design choice: it preserves the original aspect ratio of input images instead of forcing a resize to a fixed square. A 1920x1080 screenshot and a 640x640 satellite tile get encoded with their native proportions intact.
The more interesting feature is configurable image token budgets. You can control how many tokens each image consumes: 70, 140, 280, 560, or 1120 tokens. This gives you a direct knob to trade off between visual detail and inference speed.
.png)
At 70 tokens, the model gets a rough sketch of the image: enough for scene classification or high-level question answering. At 1120 tokens, it receives enough detail for OCR, small object detection, and document layout analysis. This is different from most competing VLMs, which use a fixed token count per image and give you no control over the compute-accuracy trade-off.
If you are running Gemma 4 in a pipeline that processes thousands of images (think quality inspection on a production line), dropping from 1120 to 280 tokens per image cuts your per-image cost by 4x while keeping enough spatial information for defect classification. That kind of flexibility is rare in open-weights models.
4. Vision Capabilities: What Gemma 4 Can Do
The raw benchmark numbers tell one story. The practical capabilities tell another. Let’s look at both.
Native Bounding Box Output
Gemma 4 can output bounding box coordinates directly in its response. You prompt it with an image and a detection query, and it returns structured JSON:
[
{"box_2d": [142, 35, 420, 310], "label": "forklift"},
{"box_2d": [500, 200, 680, 440], "label": "pallet"},
{"box_2d": [60, 310, 195, 490], "label": "safety_cone"}
]The coordinate format is [y1, x1, y2, x2], which matches the convention used by TensorFlow Object Detection API (and differs from the [x1, y1, x2, y2] format used by COCO and most PyTorch-based detectors). Keep that in mind when integrating Gemma 4 output into existing pipelines. A coordinate swap is trivial but easy to miss.
This native detection capability is worth comparing to dedicated object detection models. Gemma 4 will not match a fine-tuned YOLOv11 on speed or mAP for a fixed set of classes. But it handles open-vocabulary detection out of the box: ask it to find “dented cans on the conveyor belt” and it will try, without any training on dented cans. For prototyping and low-volume detection tasks, that removes a lot of annotation work. Our guide to fine-tuning VLMs for image understanding covers the broader theory behind why this approach works.
Video Understanding
All four Gemma 4 models process video at up to 1 frame per second for sequences up to 60 seconds. The model receives frames as a sequence of image tokens interleaved with temporal position information. You can ask it to describe activity, detect events, or answer questions about what happened in the clip.
Sixty seconds at 1 fps gives you 60 frames. At 280 tokens per frame, that consumes 16,800 tokens of context, well within the 128K window of even the smallest E2B variant. At 1120 tokens per frame, you hit 67,200 tokens, still manageable but a consideration for batch processing.
OCR and Document Understanding
Gemma 4 handles OCR, chart comprehension, PDF reading, and GUI element detection. The 31B model in particular performs well on document-heavy benchmarks, scoring competitively on DocVQA and ChartQA tasks. For CV engineers working with industrial documents (inspection reports, shipping labels, work orders), this means a single model can both read text from images and reason about the visual layout.
If you are building OCR pipelines, take a look at our walkthrough on chain-of-thought prompting for VLMs, which covers how to structure multi-step reasoning queries that improve extraction accuracy on complex documents.
Benchmark Numbers
Here are the numbers that matter for vision practitioners:
.png)
The 31B dense model places third on the Arena AI Text leaderboard among open models. The 26B MoE trails slightly on accuracy benchmarks but achieves those scores while activating only 3.8B parameters per token. For inference-constrained deployments, the 26B is the more interesting model.
Google has not published a full research paper for Gemma 4. The model card is the only primary source as of release day. Expect more detailed evaluations from the community in the coming weeks.
The benchmarks above reflect the 26B and 31B models on server hardware. But Gemma 4's most unusual bet is at the other end of the size spectrum.
.png)
5. Edge Deployment: The E2B Story
This is where Gemma 4 stands apart from every other open-weights VLM released in 2026.
The E2B model runs on a Raspberry Pi 5. Not a cloud GPU. Not a workstation with an RTX 4090. A $80 single-board computer with 8 GB of RAM. Google published the following numbers for E2B on Raspberry Pi 5:
- Prefill: 133 tokens/second
- Decode: 7.6 tokens/second
- Memory footprint: Less than 1.5 GB
These numbers assume INT4 quantization, which is how Google tested the Raspberry Pi deployment. At 7.6 tokens per second for decoding, you can generate a 100-token bounding box response in about 13 seconds. That is not real-time. But for many edge vision applications (agricultural monitoring, periodic quality checks, warehouse inventory scanning), sub-15-second response times are acceptable. The model fits comfortably in memory alongside other processes, leaving room for image capture, preprocessing, and I/O handling.
Google lists official support for Android, iOS, Windows, Linux, macOS, and WebGPU (in-browser inference). That last one is interesting: a Gemma 4 E2B model running vision inference in a web browser opens up deployment scenarios that skip server infrastructure entirely. For teams exploring on-device inference on Android, the E2B gives you a multimodal model that fits within mobile memory constraints.
.png)
What E2B Means for CV Pipelines
Most open-weights VLMs in the 7B+ range require at least a consumer GPU for usable inference speeds. Models like Qwen 3.5’s smallest variant (0.8B) run on phones, but their vision capability is limited at that scale. Gemma 4’s E2B occupies a different niche: it is small enough for device deployment but carries 2.3B effective parameters, which is enough capacity to handle structured output tasks like bounding box detection and document OCR.
Consider a concrete scenario. You are building a quality inspection system for a manufacturing facility. You want cameras at each station running local inference, no cloud dependency, no latency from network round-trips. With E2B, you can run a multimodal model on a $80 board at each station. It reads the image, outputs detection coordinates and labels, and flags anomalies. Will it match a fine-tuned YOLO model’s throughput? No. But it handles open-vocabulary queries without retraining, and that flexibility saves weeks of annotation work for new defect types.
6. Competitive Comparison: Gemma 4 vs. The Field
Open-weights VLMs have gotten crowded in 2026. Gemma 4 enters a field where Qwen 3.5, Llama 4 Scout, and several Chinese models (GLM-5, Kimi K2.5) are all competing for the same audience. Here is an honest breakdown.
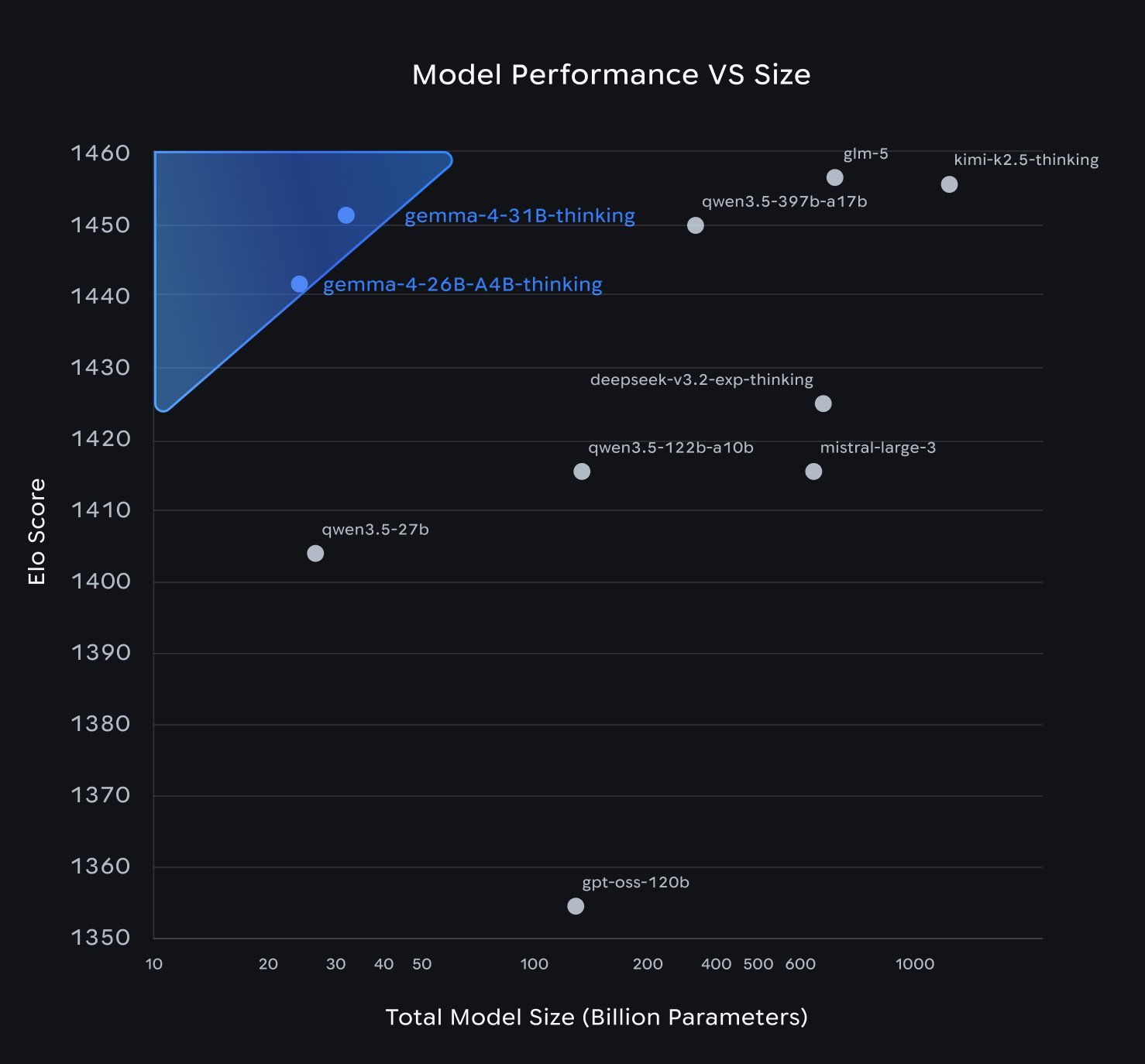
Gemma 4 31B vs. Qwen 3.5 27B
These are the two closest competitors in the “large open-weights VLM” category.
- GPQA Diamond: Qwen 3.5 and Gemma 4 31B score within a fraction of a percent of each other on early community evaluations. Close enough to call it a tie, though official numbers from Google's model card do not include this benchmark.
- MMMU Pro: Gemma 4 31B leads at 76.9% vs. Qwen 3.5’s published scores on the same benchmark.
- Architecture: Qwen 3.5 uses a hybrid Gated DeltaNet + full attention layout (75% linear, 25% quadratic). Gemma 4 uses sliding-window + global attention hybrid. Different engineering bets on the same problem.
- Edge story: Qwen 3.5’s smallest model is 0.8B. Gemma 4 E2B is 2.3B effective but runs on a Raspberry Pi with published benchmarks. Qwen has not published comparable edge numbers.
- License: Both Apache 2.0. No difference here.
If you want a deeper look at how Qwen 3.5 compares across its full model family, we published a guide to fine-tuning Qwen2.5-VL that covers the fine-tuning workflow for Qwen’s vision models.
Gemma 4 vs. Llama 4 Scout
Meta’s Llama 4 Scout uses a 17B active parameter MoE. It targets multi-image and long-context reasoning. Gemma 4’s 26B MoE (3.8B active) is much smaller in effective compute cost, which gives it an edge on latency and memory. Llama 4 Scout is stronger for tasks requiring sustained reasoning across many images, while Gemma 4 wins on deployment flexibility, especially at the edge.
The Chinese Competition
GLM-5 from Zhipu AI and Kimi K2.5 from Moonshot AI outperform Gemma 4 on several benchmarks. That is worth acknowledging. These models are less commonly deployed in Western production environments due to documentation availability, community tooling, and ecosystem integration, but their raw capability is high. On reasoning-heavy benchmarks, GLM-5 in particular has shown strong results.
.png)
Where Gemma 4 Wins and Loses
Gemma 4 leads on:
- Edge deployment (E2B has no open-weights VLM competitor at its size and capability)
- Platform coverage (Android, iOS, browser, desktop, Linux, RPi)
- License permissiveness (first Apache 2.0 release in Gemma line)
- Configurable image token budgets (unique among major VLMs)
- Native bounding box output format
Gemma 4 trails on:
- Peak benchmark scores (GLM-5 and Qwen 3.5 score higher on several evals)
- Context length at the top end (256K vs. Qwen 3.5’s 1M tokens)
- Documentation depth (no research paper yet, only a model card)
- Community tooling maturity (Qwen and Llama have larger fine-tuning ecosystems)
7. Fine-Tuning Gemma 4 for Vision Tasks
Apache 2.0 means you can fine-tune Gemma 4 on proprietary data and deploy the result commercially without restrictions. For CV engineers, the question is which model size to fine-tune and on what.
Choosing a Model Size for Fine-Tuning
If your target is edge deployment, start with E4B (4.5B effective). It is large enough to hold useful learned representations but small enough to fine-tune on a single consumer GPU with LoRA or QLoRA. The E2B is tempting for its tiny footprint, but 2.3B parameters leaves less room for task-specific adaptation.
For server-side deployments where accuracy matters most, the 26B MoE is the sweet spot. You get near-31B accuracy at a fraction of the inference cost, and MoE models respond well to fine-tuning individual expert subsets for domain-specific tasks.
If you have worked with PaliGemma (Google’s earlier vision-language model), the fine-tuning workflow will feel familiar. Our primer on fine-tuning PaliGemma and VLMs covers the general approach, which applies to Gemma 4 with adjustments for the new architecture.
Practical Fine-Tuning Considerations
- Dataset format: Gemma 4 expects interleaved image-text input. For detection tasks, structure your training data with image inputs and JSON-formatted bounding box targets using the
[y1, x1, y2, x2]coordinate format. - Token budget during training: Match your training token budget to your inference budget. If you plan to deploy at 280 tokens per image, train at 280 tokens. Mismatched budgets between training and inference degrade performance.
- LoRA rank: For the E4B, start with rank 16-32. For the 26B MoE, the architecture includes a shared expert (always active, handles common patterns) alongside 127 routed experts (specialized, activated selectively). Experiment with expert-specific LoRA adapters applied only to the routed experts while keeping the shared expert frozen. This preserves general capability while adapting the specialized pathways to your domain.
- Evaluation: Use your domain-specific metrics (mAP for detection, accuracy for classification) rather than general VLM benchmarks. A model that scores lower on MMMU but higher on your factory defect dataset is the better model for your use case.
8. Datature Vi: Gemma 4 on the Roadmap
Datature’s Vi platform currently supports VLM fine-tuning for Qwen3-VL, InternVL, and NVIDIA Cosmos-Reason2. Gemma 4’s architecture (decoder-only transformer with a vision encoder) fits the pattern that Vi already handles. The Apache 2.0 license removes commercial friction that previous Gemma versions introduced.
Gemma 4 is on Vi’s roadmap. Vi operates on a credit-based pricing model, and Gemma 4’s range of model sizes (from 2.3B to 30.7B active parameters) would give Vi users options across the cost-accuracy spectrum. For teams looking to build on Gemma 4 today, the fine-tuning workflow from our containerized VLM deployment guide covers the infrastructure patterns that apply once a model is trained.
9. What This Means for CV Engineers
Gemma 4 does not rewrite the rules of computer vision. But it pushes several boundaries at the same time.
Edge vision just got a real open-weights option. Before Gemma 4, running a capable VLM on a Raspberry Pi was not practical with open models. The E2B changes that. If you have been waiting for a multimodal model that runs on cheap hardware with a permissive license, this is it.
Configurable token budgets are a deployment multiplier. Being able to dial image resolution up or down per image is something production pipelines need. Fixed-token models force you to choose between over-processing simple images and under-processing complex ones. Gemma 4 lets you adapt per query.
The open-weights VLM landscape is now a three-way race. Qwen 3.5, Llama 4, and Gemma 4 are all Apache 2.0 (or equivalent), all multimodal, and all competitive on benchmarks. The differentiators are now architectural trade-offs, edge support, and ecosystem maturity. That competition benefits everyone building with these models.
Missing pieces to watch for. No research paper means no detailed ablation studies, no training data composition disclosure, no safety evaluation details, and no reproducibility information. If you are deploying vision models in domains involving people (workplace safety, security, healthcare), the lack of documented safety evaluations and content filtering behavior is a gap you need to fill with your own testing. Google is likely holding the paper for a conference submission. Until it drops, treat benchmark claims with appropriate skepticism and validate on your own data.
FAQ
What is the difference between Gemma 4 and Gemini 4?
Gemma 4 is Google’s open-weights model family, released under Apache 2.0. Gemini is Google’s proprietary API model. Gemma 4 weights are downloadable, fine-tunable, and commercially deployable. Gemini is only accessible through Google’s API.
Can Gemma 4 replace a dedicated object detection model like YOLO?
Not for high-throughput production use cases. Gemma 4’s native bounding box output is useful for open-vocabulary detection and prototyping, but a fine-tuned YOLO model will be 10-100x faster for fixed-class detection at scale. Use Gemma 4 for flexible, zero-shot detection and YOLO for speed-critical production pipelines.
Which Gemma 4 model should I use for edge deployment?
Start with E2B (2.3B effective parameters) if your hardware is a Raspberry Pi, phone, or low-power device. It runs at 7.6 tokens per second on a Raspberry Pi 5 with under 1.5 GB of memory. Use E4B (4.5B effective) if you have a mid-range laptop or tablet with more headroom.
Is Gemma 4 better than Qwen 3.5 for computer vision?
It depends on the deployment target. Qwen 3.5 scores slightly higher on some benchmarks and supports up to 1M token context. Gemma 4 has better edge deployment options and configurable image token budgets. For cloud inference with maximum accuracy, Qwen 3.5 edges ahead. For on-device or browser-based vision, Gemma 4 wins.
Does Gemma 4 support video input?
Yes. All four Gemma 4 models process video at up to 1 frame per second for clips up to 60 seconds. The two smaller models (E2B and E4B) also accept audio input alongside video and images.
.png)

