


The Cost of Breaking on Every Changeover
A product changeover on a manufacturing line is supposed to take minutes. Swap the tooling, load the new recipe, run verification parts, start production. For the mechanical systems (conveyors, robots, feeders), this process is well understood and highly optimized.
The vision system is the bottleneck.
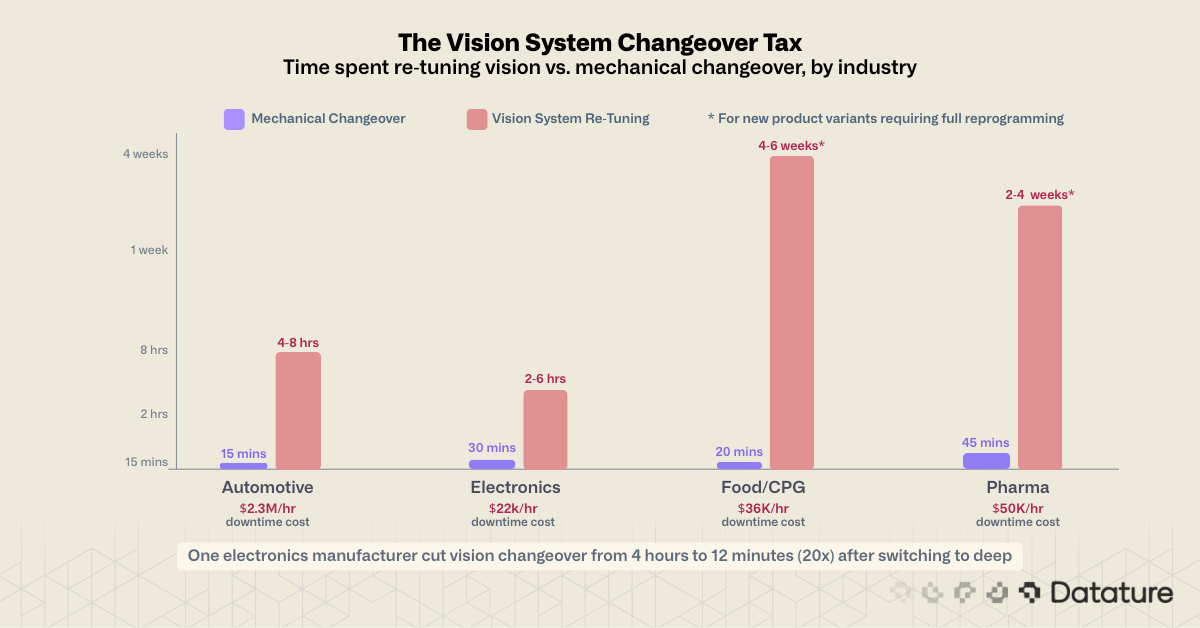
According to a 2024 Siemens report on manufacturing downtime, unplanned downtime costs manufacturers billions annually. Industry estimates put vision system reprogramming for new product variations at four to six weeks in complex cases. Not four to six hours. Weeks. This happens because the inspection logic is hard-coded to specific visual features: the exact outline of a part, the expected reflectance of a surface, the precise pixel coordinates of a label. Change any input, and the logic produces false rejects, missed defects, or both.
The financial impact is direct. The same Siemens research found that unplanned downtime costs up to $2.3 million per hour in automotive manufacturing and $36,000 per hour in food and consumer goods. Even if vision system recalibration accounts for a fraction of that total, the accumulated cost across dozens of changeovers per year is substantial. One electronics manufacturer documented a reduction from four hours of changeover downtime to 12 minutes after switching to vision-guided calibration, a 20x improvement.
For high-mix low-volume (HMLV) manufacturers, the math is even worse. A contract manufacturer running 50+ SKUs per week cannot afford to retune a vision system for each one. If changeover takes as long as production, automated inspection becomes a net cost rather than a productivity gain.
What Traditional Machine Vision Actually Does (and Why It Breaks)
Before examining the AI offerings from Cognex and Keyence, it helps to understand what most deployed machine vision still runs on. The marketing may say "AI-powered," but the installed base tells a different story.
Template Matching
Template matching is the most widely deployed technique in manufacturing vision. The system stores a reference image (the "golden template") and compares it to each captured frame using a pixel-by-pixel comparison that produces a similarity score (technically called normalized cross-correlation). The math is straightforward: slide the template across the image, compute the similarity at each position, and report the location and score of the best match. A score above a threshold (e.g., 0.85) means "found"; below means "missing" or "misaligned."
In tools like Cognex PatMax and Keyence's pattern search, geometric pattern matching extends basic NCC by extracting edge features from the template and matching those features under rotation, scale, and minor perspective changes. PatMax can handle +/-180 degrees of rotation and modest scale variation, which makes it more tolerant than pixel-level correlation. But the template itself is still frozen at programming time.
Why it breaks on changeovers: The template is specific to one product variant. A new SKU with a different label layout, a different cap color, or a slightly different part geometry requires a new template. Engineers on high-mix lines maintain libraries of hundreds of templates and write recipe-switching logic to select the right one per product code. When a new product is introduced that no template exists for, the line stops until an engineer captures reference images, defines search regions, tunes the acceptance threshold, and validates against boundary samples. For a contract manufacturer adding 5-10 new SKUs per month, this is a permanent tax on throughput.
Threshold-Based Inspection and Blob Analysis
Threshold inspection converts a grayscale image into a binary (black/white) image by selecting a brightness cutoff. Every pixel above the threshold becomes white (foreground); every pixel below becomes black (background), or vice versa. Blob analysis then identifies connected regions of foreground pixels and measures their properties: area (pixel count), centroid (center of mass), aspect ratio, perimeter, compactness, and bounding rectangle.
This pipeline powers the majority of defect detection in traditional systems. A "good" part produces blobs within expected area and shape ranges; a defective part produces blobs that are too large (contamination), too small (missing material), or in the wrong position. Cognex's VisionPro blob tool and Keyence's CV-X pattern inspection both operate on this principle.
The critical weakness is the threshold value itself. Consider a surface inspection where the threshold is set to 128 (out of 255). On a light-colored plastic part against a dark conveyor, this separates part from background cleanly. Switch to a dark-colored part on the same conveyor, and the threshold no longer isolates the part at all, because the part and background are now similar brightness. Adaptive thresholding (Otsu's method, local adaptive thresholds) helps in some cases, but fails when the contrast between defect and surface is low or when the surface has inherent texture variation that produces threshold noise.
Why it breaks on changeovers: The threshold assumes consistent brightness, contrast, and surface reflectance. A product with a different surface finish (matte vs. glossy), a different color, or a different background material will produce completely different binary images from the same threshold. Engineers retune threshold values for each product/background combination, often by trial and error across dozens of sample parts. When lighting drifts due to bulb aging, seasonal ambient light changes, or lens contamination, the thresholds drift with it. On a line running continuously, this drift can cause a gradual rise in false rejects that goes unnoticed for weeks.
Edge Detection and Geometric Measurement
Edge detection finds boundaries where pixel intensity changes sharply. The most common operators (Sobel, Canny) compute image gradients in X and Y directions and flag locations where the gradient magnitude exceeds a threshold. Sub-pixel edge detection refines these locations to fractions of a pixel for dimensional accuracy. Combined with calibration (mapping pixels to millimeters using a known reference target), edge detection becomes the basis for precision measurement: distances between features, hole diameters, angle verification, and concentricity checks.
This is where traditional machine vision excels and where deep learning offers no direct replacement. A calibrated edge measurement system can achieve repeatability below 0.01mm, which no classification or segmentation model can match.
Why it breaks on changeovers: Edge detectors assume that the features of interest produce the strongest gradients in the image. On a new product with different surface texture (machining marks, grain patterns), embossed markings, or rounded edges instead of sharp ones, the edge detector may lock onto the wrong features or miss the correct ones. Every product variant needs its own set of search regions, edge polarity settings (light-to-dark vs. dark-to-light), contrast thresholds, and filter widths. A recipe that works for a machined aluminum part will fail on a molded plastic part, even if the dimensional checks are identical, because the edge characteristics are different.
The Common Thread
Good lighting design (structured illumination, dome lights, backlighting, telecentric optics) reduces the severity of these problems. Controlled lighting narrows the range of visual variation that the software has to handle. But lighting control mitigates the changeover problem; it does not eliminate it. When the product itself changes, no amount of lighting engineering makes a template match a part it was never programmed for.
All three techniques share the same failure mode: they encode specific assumptions about how the product looks under specific conditions. Those assumptions are set by engineers at programming time and cannot adapt at runtime. When reality deviates from assumptions, the system produces errors. The response is always the same: an engineer returns to the line, captures new reference data, and re-programs the inspection. This cycle is the root cause of changeover downtime for machine vision.
.png)
What Cognex and Keyence AI Can Actually Do
Both companies have invested heavily in adding AI capabilities to their product lines. To criticize them fairly, we need to understand what they offer in detail, because parts of it are genuinely useful. The question is where the ceiling is.
Cognex: Edge Learning + VisionPro Deep Learning
Cognex offers two tiers of AI.
Edge Learning runs directly on Cognex In-Sight smart cameras (the 2800 and 3800 series, as well as the earlier D900 for on-camera deep learning inference). It uses pre-trained neural network backbones that Cognex has trained on broad industrial image datasets. Users fine-tune the last layers by showing 5-10 example images per class. Training takes minutes, runs on-device, and requires no GPU or programming expertise. Edge learning supports classification, presence detection, OCR, and assembly verification.
This is legitimate machine learning, and for straightforward tasks (sorting parts by type, detecting the presence of a connector, reading lot codes), it works well. The 5-10 image requirement is real, not marketing fiction, because the pre-trained backbone already understands general visual features. Edge learning is a genuine step up from template matching.
VisionPro Deep Learning (VPDL), formerly known as ViDi, is a PC-based deep learning platform built from two acquisitions: ViDi Systems (Switzerland, 2017) and SUALAB (South Korea, acquired for $195 million in 2019). VPDL offers four specialized tools: Blue Locate (object detection), Red Analyze (pixel-level defect segmentation), Green Classify (image classification), and Blue Read (OCR). These tools can be chained together for multi-step inspection workflows.
VPDL requires hundreds of labeled images for training, an NVIDIA GPU with 10GB+ VRAM, a Windows PC, and a physical USB security dongle on every machine running the software. Training licenses start at approximately $995/year, and each inspection station needs its own PC, GPU, and dongle. There is no cloud option, no Linux support, and no browser-based interface.
What VPDL Cannot Do
Users cannot import custom models (no ONNX, no PyTorch, no TensorFlow). Users cannot export trained models to run outside the Cognex ecosystem. There is no automated active learning. The architecture is proprietary and fixed. Retraining requires manual intervention: collecting new images, relabeling, and re-running training.
Keyence: Edge Learning in a Black Box
Keyence's AI story is concentrated in three product families.
The IV4 Series vision sensors feature AI Identify, AI Count, AI OCR, and AI Differentiate tools. AI Differentiate can classify parts as good or defective using as few as two training images. Processing speed reaches 250 parts per second. Setup follows a three-step guided process designed for operators, not engineers.
The VS Series is Keyence's most AI-capable product, offering AI Segmentation, AI Detection, AI Classification, and AI OCR. It trains from approximately 20 images on average, runs on a general-purpose PC (no GPU required), and can combine AI tools with rule-based tools on the same image. The VS Series supports up to 32 classification categories.
The CV-X Series uses an "Auto-Teach" approach where the system learns from 30-50 good parts and flags deviations. This is one-class anomaly detection: learning what "normal" looks like and rejecting anything different.
Keyence's AI is designed to be invisible to the user. Operators show the system good and bad parts, and the system figures out the classification boundary. This ease-of-use is real and praised by users in reviews. One integration firm described it as requiring "no special expertise to program."
What Keyence Cannot Do
Like Cognex, Keyence's AI is a complete black box. No custom model import, no model export, no architecture selection, no hyperparameter tuning, no visibility into what the model has learned. There is no documented active learning. There is no user-facing data augmentation. The IV Series has known limitations with dark-colored parts due to contrast issues. Multiple cameras cannot fire simultaneously on certain models.
Where Both Companies Hit Their Ceiling
For stable, well-defined inspection tasks with limited variability, both Cognex and Keyence's AI products are a real improvement over pure template matching. They handle moderate lighting variation, minor positional shifts, and small cosmetic differences that would break threshold-based systems.
The ceiling appears when:
- Defect variability is high: Edge learning's pre-trained backbone can only generalize so far. A scratch on brushed aluminum looks nothing like a scratch on anodized aluminum, and both look nothing like a surface contaminant. When the defect types are varied and subtle, 5-20 training images are not enough.
- Product mix exceeds the model's training set: A model trained on 10 SKUs will struggle with SKU #11 if its visual characteristics differ from the training distribution. Retraining is manual and requires capturing new images and relabeling.
- Production conditions drift: Lighting ages, camera lenses get dirty, conveyor surfaces wear. Neither platform's deployed models adapt to these gradual changes automatically. When accuracy degrades, someone has to notice, collect new data, and retrain.
- Novel defect types appear: A new failure mode that was not in the training data (a previously unseen material contamination, a new supplier's component with a different surface texture) will be missed entirely. There is no mechanism for the system to flag "I'm not sure about this one" and request human review.
This last point, the absence of active learning, is the most consequential gap. It is the difference between a system that gets better over time and a system that silently degrades until someone notices the false reject rate climbing.
.png)
The Active Learning Gap
Active learning is a training strategy where the model identifies which unlabeled samples would be most informative for improving its performance and asks a human to label only those samples. In a manufacturing context, this means the inspection system flags parts it is uncertain about, a human reviews those flagged parts, and the labels feed back into the next model update.
This creates a feedback loop: the model improves on exactly the edge cases that matter, without requiring engineers to collect and label large datasets from scratch. Over time, the system becomes more accurate on the specific defect types and product variants that appear on that production line.
Key Finding
Neither Cognex nor Keyence implements an automated active learning loop. Both require manual retraining initiated by a human operator.
To be fair, some system integrators build active learning pipelines on top of Cognex or Keyence hardware by extracting images programmatically and routing them through external labeling and retraining workflows. The limitation is in the vendor's software platform, not the camera hardware itself. But this requires custom integration work that the vendor does not provide or support out of the box.
Cognex offers "outlier score tracking" that monitors for environmental changes and flags unusual images, but this is a passive monitoring capability, not an automated data selection and retraining pipeline. Retraining in Cognex is always a manual process initiated by the user.
Keyence's marketing mentions "adaptive learning" that "continuously enhances accuracy by adapting to new data and recognizing evolving patterns." Based on the technical documentation, this appears to mean that the system supports easy manual retraining through its no-code interface, not that it automatically identifies uncertain samples and incorporates new labels without human initiation.
The distinction matters because manual retraining is reactive. You notice a problem (rising false reject rate, missed defects found downstream), then collect data, then retrain. The system was degrading the entire time you weren't watching. With active learning, the system tells you proactively that it is encountering cases outside its training distribution, before those cases turn into escaped defects or unnecessary scrap.
For a deeper technical treatment of how active learning works in computer vision pipelines, including query strategies and sampling methods, see Datature's guide to active learning.
.png)
How Deep Learning Solves the Changeover Problem
Modern deep learning, when deployed on a platform designed for iterative model improvement, addresses the changeover problem at its root. Instead of encoding rigid assumptions about how a product should look, a deep learning model learns a flexible representation of what "good" and "defective" look like across the full range of product variants, lighting conditions, and defect types.
.webp)
Transfer Learning: New SKU, Minimal Data
When a new product variant appears on the line, a deep learning model does not start from scratch. Transfer learning takes a model already trained on related products and fine-tunes it on a small set of images from the new variant. With 50-200 labeled images of the new SKU (far fewer than training from scratch), the model adapts its learned features to the new context while retaining its understanding of general defect patterns.
This works because the AI already knows what scratches, edges, textures, and surface patterns look like from training on millions of images. For a new SKU, it only needs to learn the product-specific details, which takes a fraction of the data and time compared to starting from zero. Fine-tuning takes minutes to hours, not weeks.
A common concern is whether deep learning can keep up with line speeds. On compact industrial AI processors designed for factory-floor deployment, modern detection models inspect each image in 15-60 milliseconds. That translates to 15-60+ frames per second, fast enough for the vast majority of manufacturing lines. For very high-speed applications (1,000+ parts per minute), smaller model variants or hardware-accelerated configurations close the gap.
The practical impact: a changeover that required weeks of reprogramming with traditional vision can be completed in a day or less with transfer learning. Capture images of the new SKU during the mechanical changeover, label them (or use AI-assisted labeling to speed this up), fine-tune, validate, and deploy.
For an introduction to how few-shot and zero-shot approaches further reduce the data requirement, see our guide to zero-shot and k-shot learning.
Data Augmentation: More From Less
Data augmentation generates synthetic training variations from existing images: rotations, flips, brightness shifts, contrast changes, noise injection, and geometric distortions. A dataset of 100 real images becomes, in effect, thousands of training examples.
Neither Cognex nor Keyence offers user-configurable augmentation as a first-class feature. Cognex's VPDL includes basic augmentation options (flip, rotate, blur, noise) in its training GUI, but the defaults are opaque and tuning is limited. Keyence's approach is to minimize the need for augmentation by optimizing image capture conditions, which works until conditions change in ways you did not anticipate.
Modern deep learning platforms treat augmentation as a core part of the training pipeline, with full control over which transformations to apply and how aggressively. When your training set is small (as it usually is after a changeover), augmentation is the difference between a model that generalizes and one that memorizes.
.png)
Datature advocates strongly for image augmentation (either augmented or synthetic datasets) because real-world enviroments can have deviations from the datasets. Could be inconsistent lighting, orientation, and visual artifacts such as motion blur. This way, we enable the models to learn to identify defects even under this conditions - so that teams have confidence on the actual production line that these AI will detect the anomalies.
Continuous Improvement Through Production Data
The most important difference between a modern deep learning platform and a traditional machine vision system is not the accuracy on day one. It is what happens on day 30, day 90, and day 365.
A well-designed deployment pipeline captures images from production, flags uncertain predictions, routes them for human review, and feeds confirmed labels back into periodic retraining cycles. The model improves on the specific challenges of your production line, because it learns from the exact images your cameras capture under your lighting, with your products, at your line speeds.
Traditional machine vision has no equivalent to this. The inspection logic on day one is the inspection logic on day 365, unless an engineer manually intervenes. The system does not know what it does not know.
Open Architecture: Your Model, Your Hardware
Both Cognex and Keyence use proprietary model architectures that cannot be inspected, exported, or transferred. If you decide to switch vendors, your training data stays useful but your trained models do not. You start over.
Open deep learning platforms work differently. Models can be exported in industry-standard formats that run on any compatible hardware, and combined with custom pre-processing or post-processing logic. Your training investment is portable. If you switch vendors or upgrade hardware, your models come with you.
This also means you are not locked into a specific camera vendor. Modern industrial cameras from Basler, FLIR (Teledyne), IDS, and Allied Vision all support industry-standard communication protocols. The camera captures the image; the software does the inspection. Separating these two concerns means you can upgrade either one independently.
The Hybrid Architecture: Deep Learning + OpenCV
In practice, the most effective manufacturing inspection systems combine deep learning and traditional computer vision in a two-stage pipeline. Deep learning handles the hard part (localization under variable conditions), and traditional measurement software handles the precise part (calibrated measurement within the localized region).
Here is how it works. A deep learning detection model runs on the full camera frame and draws bounding boxes around parts, features, or regions of interest. The model does not care about threshold tuning or template libraries. It has learned to recognize the object across lighting changes, orientation shifts, and surface variations. This solves the changeover problem at the localization step.
Once you have a bounding box, you crop that region and pass it to traditional measurement software. Inside the cropped region, the part is centered and consistently framed, which makes traditional techniques reliable again. Edge detection finds boundaries, contour analysis extracts part outlines, and calibrated pixel-to-millimeter mapping produces dimensional measurements: width, height, diameter, gap spacing. Because the deep learning model has already isolated the part, the measurement pipeline does not need to search the entire image or fight background clutter.
Example 1: Electronics. Inspecting PCB connectors on a mixed-model assembly line. The AI detects each connector regardless of board layout or connector type. For each detected connector, measurement software checks pin spacing to verify it falls within tolerance (e.g., 2.54mm +/- 0.05mm). The detection model adapts to new board designs with minimal retraining; the measurement logic stays the same because pin spacing standards do not change.
Example 2: Food processing. A snack food manufacturer runs 40+ SKUs on the same packaging line. The AI detects each sealed package regardless of label design, bag size, or fill level. Traditional measurement tools then verify seal width and check for gaps in the seal area. When a new product launches with a different bag format, the detection model is retrained with 50-100 images of the new package. The seal measurement criteria stay the same because food safety sealing standards are constant.
In plain terms: the AI finds the part, and the measurement software measures it. The AI adapts to new products. The measurement logic stays the same because physical tolerances do not change with product layout.
.png)
For Your Engineering Team
A working Python implementation of the measurement stage (using OpenCV for edge detection, contour extraction, and calibrated pixel-to-millimeter conversion) is available in the Datature developer documentation. The function takes a camera frame and bounding box as inputs, crops the region of interest, finds edges, measures the largest contour's dimensions, and returns a pass/fail result against configurable tolerances.
Building an Adaptive Inspection System: A Practical Path
Moving from a rigid, recipe-based vision system to one that adapts with the line does not require ripping out your cameras or replacing your PLCs. The transition can be incremental.
Step 1: Audit Your Current Failure Modes
Before adopting any new technology, catalog where your current vision system fails. Which changeovers require the most re-tuning time? Which SKUs have the highest false reject rates? Which defect types escape inspection most often? This audit identifies the highest-value targets for deep learning deployment.
Step 2: Start With the Hardest Problem
Pick the single inspection task that causes the most changeover pain. This is usually cosmetic defect detection on variable products (scratches, dents, discoloration, contamination), because cosmetic defects have the highest variability and are the hardest to express as rules. Train a deep learning model on this task while keeping traditional vision for everything else.
Step 3: Collect and Label Production Data
Use your existing cameras to capture images during production. The quality of your training data determines the quality of your model. AI-assisted annotation tools (including SAM-based segmentation) can reduce labeling time by 50-80% compared to manual polygon drawing.
Step 4: Train, Validate, Deploy, Monitor
Train a model on your labeled data. Evaluate it against a held-out test set that represents real production variability. Deploy it alongside your existing system in shadow mode (both systems inspect every part, but only the traditional system makes reject decisions) to validate accuracy before going live. Monitor model confidence scores to catch degradation early.
Step 5: Close the Loop
Set up a pipeline where low-confidence predictions are flagged for human review. As confirmed labels accumulate, retrain the model periodically. Each retraining cycle improves accuracy on your specific production conditions. This is the active learning loop that neither Cognex nor Keyence provides out of the box.
.png)
Where Datature Fits
Datature's Nexus platform is built for exactly this workflow. Here is how it maps to the problems described in this article:
- Your quality team labels the images, not a contractor. Nexus includes AI-assisted annotation tools that let your inspectors mark defects by clicking, not coding. A quality engineer who knows what a bad weld looks like can label training data in hours, not weeks.
- Training happens in the browser, not on a dedicated workstation. No GPU to purchase, no software to install, no USB dongle. Select a model architecture, configure data augmentation, and start training. Monitor progress with training graphs and evaluate results with confusion matrices.
- Models export in standard formats for any hardware. Deploy on your existing edge devices or industrial PCs. No vendor lock-in. If you switch hardware in two years, your trained models come with you.
- Works with your existing cameras. Basler, FLIR, Keyence, IDS, Allied Vision. Any camera that outputs standard image formats feeds into Nexus. You are not replacing your camera infrastructure.
- New SKU? Retrain in hours, not weeks. Capture 50-200 images of the new product, label them with AI assistance, fine-tune the existing model. Your quality team can do this during the mechanical changeover.
Cost and ROI: What to Expect
The most common question from quality leaders evaluating deep learning platforms: "What does this actually cost, and how do I justify it to my CFO?"
Platform costs for deep learning inspection typically fall into three tiers:
.png)
Typical Pilot Timeline that we see as we engage with factories,
.png)
ROI Drivers ↘
- Reduced changeover downtime (hours to minutes per SKU switch)
- Lower false reject rate (less good product scrapped)
- Fewer defect escapes (less warranty cost, fewer customer complaints)
- Reduced inspection staffing requirements (especially for hard-to-fill third shift)
- Eliminated per-station dongle and license costs over time
For a facility running 20+ changeovers per month with 2-4 hours of vision re-tuning per changeover, even modest improvements represent six-figure annual savings. The pilot itself typically costs less than a single Cognex VPDL workstation.
What to Ask Any AI Inspection Vendor
If you are evaluating deep learning inspection platforms, these questions will separate the serious solutions from the marketing. Bring this list to every vendor demo.
- "Can my quality team label training data without writing code?" If the answer involves Python scripts or command-line tools, your team will not use it. Look for a visual interface where operators mark defects by clicking on images.
- "How many images do I need for a new product, and how long does training take?" Good answers: 50-200 images, training in hours. Red flag answers: "it depends" with no specifics, or thousands of images required.
- "What happens when a new defect type appears that was not in the training data?" Look for: anomaly detection (flags anything unusual), active learning (routes uncertain cases for human review), easy retraining. Red flag: "you need to collect a new dataset and retrain from scratch."
- "Can I export my trained model and run it on different hardware?" If the vendor says no, you are locked in. Ask specifically about standard export formats and whether models run on third-party edge devices.
- "Does the system work with my existing cameras?" Any platform that requires proprietary cameras is adding unnecessary cost. Standard industrial cameras from any major manufacturer should work.
- "What does a changeover look like with your system vs. what I do today?" Ask them to walk through a specific scenario: new SKU, different surface finish, same inspection criteria. How many images? How long to retrain? Does the line stop?
- "Can you show me a deployment at a facility similar to mine?" Case studies matter. Reference customers in your industry matter more. If they cannot provide either, they are earlier-stage than they are admitting.
- "What does year-two look like?" First-year costs are easy to quote. Ask about renewal pricing, support costs, retraining fees, and what happens if you want to add inspection stations. The total cost of ownership over 3-5 years is what your CFO will evaluate.
Frequently Asked Questions
How many images do I need to train a deep learning model for manufacturing inspection?
It depends on defect variability. For a single defect type on a consistent background, 200-500 labeled images often produce a usable model. For multi-class defect detection across product variants, 500-2,000 images per class is a more realistic starting point. Data augmentation and transfer learning from pre-trained backbones reduce these numbers. Start with what you have and improve iteratively.
Can I use my existing Basler/FLIR/Keyence cameras with a deep learning platform?
Yes. Any camera that outputs standard image formats (JPEG, PNG, BMP, TIFF) or supports GigE Vision/GenICam standards can feed images into a deep learning pipeline. You do not need to replace your camera hardware. The inspection intelligence moves from the camera vendor's proprietary software to an independent deep learning platform.
Is deep learning accurate enough for manufacturing QC?
On well-defined defect types with sufficient training data, deep learning models routinely achieve 95-99%+ accuracy. BMW's AI weld inspection system reported 100% reliability on stud weld classification in their published validation results. Food packaging defect detection using DenseNet achieved 99.93% detection of sealing defects in peer-reviewed benchmarks. The key is having representative training data and a continuous improvement loop.
How does deep learning handle defect types it has never seen before?
A deep learning model will only detect defect types it was trained on. However, anomaly detection approaches (training on "good" parts only and flagging anything unusual) can catch unknown defect types without labeled defect data. The active learning loop then captures these novel cases, routes them for human review, and incorporates them into the next training cycle so they are detected going forward.
How does Datature solve this problem?
At Datature, we have built a complete platform called Datature Nexus that allows teams to manage industrial datasets (various formats and spectrum), annotate where defects or anomalies are visually, and train a custom model that fits this dataset with high accuracy. Datature works with the likes of Fedex, Toyota, and more to create in-house models where companies have automatically updated models on the latest SKUs, parts, and more. Industrial teams usually go on to leverage deep-learning within their operations by building models for various use cases over time and have reported great ROI.
If you'd like to learn more or discuss use cases → Contact Us
.png)
.png)
