
.png)

Summary
Computer vision in agriculture has crossed the pilot phase. Industry estimates suggest 35-45% of large agricultural operations now use some form of CV for tasks ranging from crop disease detection to produce grading (Fortune Business Insights, Mordor Intelligence estimates). According to multiple market research firms, the agricultural computer vision market is projected to reach $8.1 billion by 2030, growing at a 21.3% CAGR from 2024. But most deployments stall at the same bottleneck: generic pretrained models do not work in the field.
This report makes three arguments. First, pretrained models trained on benchmark datasets like COCO and ImageNet suffer 20-40% accuracy drops when applied to agricultural imagery because of domain shift, lighting variability, and class specificity. Second, fine-tuning on domain-specific field data - as few as 200-500 labeled images - is the proven method to close that gap. Third, edge deployment is the only viable inference architecture for field robotics: fields lack reliable internet, cloud latency exceeds actuation deadlines, and bandwidth costs at scale are unsustainable.
The companies deploying successfully - Gardyn for indoor plant monitoring, Carbon Robotics for laser-based weed elimination, Blue River Technology (John Deere) for targeted herbicide spraying with 50-80% chemical reduction - all share one pattern: domain-specific models running on edge hardware. Datature's end-to-end Vision AI platform compresses the pipeline from field data to deployed model into weeks instead of months, without requiring a dedicated ML engineering team.
The State of Computer Vision in Agriculture
Computer vision adoption in agriculture is accelerating across six primary use cases: crop disease detection, weed identification, produce grading and sorting, livestock monitoring, yield estimation, and drone-based field mapping. The technology is no longer experimental. What varies is the maturity of deployment - and the gap between a working prototype and a production system operating reliably across seasons, weather conditions, and equipment.

Four categories of companies are driving deployment. Robotics companies like Carbon Robotics (laser thermal weeding), Blue River Technology (John Deere See & Spray targeted herbicide application), and Verdant Robotics (multi-action weeding) build CV directly into autonomous field equipment. Indoor agriculture companies like Gardyn use vision models for growth monitoring and automated care in controlled environments. Ag-tech SaaS providers like Arable and Taranis process drone and satellite imagery for field-level insights. Equipment OEMs like John Deere, AGCO, and CNH Industrial are embedding CV into tractors, harvesters, and sprayers as standard features.
The common thread across all four categories: the technology works when the model knows what it is looking at. A weed detector trained on Palmer amaranth in Georgia cotton fields does not recognize waterhemp in Iowa soybean fields. A disease classifier trained on greenhouse tomato leaves fails on field-grown tomatoes under variable sunlight. The problem is not the algorithm - it is the data.
Why Pretrained Models Fail in Agriculture
Pretrained object detection and segmentation models - YOLO variants, EfficientDet, Mask R-CNN, even newer architectures like RF-DETR - ship with weights learned on benchmark datasets such as COCO (80 object classes) and ImageNet (1,000 image categories). These benchmarks contain zero agricultural imagery. No diseased tomato leaves. No weeds among corn stalks. No rain-soaked berry clusters at dawn. When you deploy these models to a field, accuracy drops 20-40% compared to benchmark performance. The reasons are structural.
Domain Shift
Domain shift is defined as the statistical difference between the data a model was trained on and the data it encounters at inference time. COCO contains photographs of everyday objects - cars, people, furniture - captured primarily in urban and indoor settings. Agricultural imagery looks nothing like this. The color distributions are different (green-dominant canopies vs. mixed-color urban scenes). The object scales are different (a 3mm aphid vs. a car). The backgrounds are different (repetitive crop rows vs. varied indoor scenes). A model that achieves 57% mAP on COCO may drop to 25-35% mAP on agricultural targets without fine-tuning.
.png)
Environmental Variability
Agricultural environments change continuously in ways that controlled datasets do not capture. Lighting shifts from dawn to noon to dusk. Rain coats leaves and changes their reflectance. Dust accumulates on camera lenses. Seasonal variation transforms the scene entirely — a bare-soil field in March becomes a dense canopy by July. A model that works in June may fail in August on the same field because the background, occlusion patterns, and light conditions have all changed. Camera angles compound the problem: a weed looks different from a forward-facing robot camera than from a downward-facing drone at 30 meters altitude.
.png)
Class Specificity
"Weed" is not a class. It is thousands of plant species, each morphologically distinct, each varying by growth stage, region, and season. A Palmer amaranth seedling in Texas looks nothing like a mature waterhemp plant in Illinois. Similarly, "disease" encompasses hundreds of conditions - early blight, late blight, powdery mildew, bacterial spot, mosaic virus - each with different visual signatures on different crops. Pretrained models have no representation for these fine-grained agricultural categories.
Scale Mismatch
Many agricultural targets are small. Early-stage disease spots span 5-20 pixels in a standard field image. Individual pests like aphids, thrips, and whiteflies are 2-5mm across. Berry-level grading requires detecting objects at 10-30 pixel resolution. Standard object detectors optimized for COCO-scale objects (typically 50-500 pixels) miss these small targets entirely. Techniques like SAHI (Slicing Aided Hyper Inference) can help at inference time, but the underlying model still needs to be trained on data that contains these small objects.
The conclusion is direct: off-the-shelf models are a starting point for architecture selection, not a deployable solution. If you are building computer vision for agriculture, fine-tuning on your specific crop, pest, disease, and field conditions is not optional - it is the minimum viable approach.
The Case for Fine-Tuning: From Generic to Field-Ready
Fine-tuning is the process of taking a model pretrained on a large general dataset and continuing training on a smaller domain-specific dataset. The pretrained backbone already understands low-level visual features - edges, textures, color gradients - from millions of images. Fine-tuning specializes the higher layers to recognize your specific targets: this specific weed species, this specific disease symptom, this specific fruit defect. The result is a model that knows your crops, your pests, and your field conditions.
How Little Data You Actually Need
Not every agricultural CV task requires fine-tuning. If you are operating in a controlled greenhouse with lighting and backgrounds similar to benchmark data, or performing simple binary classification (ripe vs. unripe) where pretrained features already discriminate well, a pretrained model with only a retrained classification head may suffice. But for the majority of field conditions, fine-tuning is necessary.
The data requirements for fine-tuning are far lower than training from scratch. For a focused detection task - identifying a single weed species or a specific disease - 200-500 well-labeled images often reach 85-93% mAP when fine-tuning from a COCO-pretrained backbone. Multi-class problems with 10+ categories typically require 1,000-3,000 images for robust generalization across field conditions. These numbers assume clean, representative labels. Annotation quality matters more than annotation quantity: 300 precisely labeled images outperform 1,000 noisy labels every time.
Fine-Tuning Mechanics
Three common strategies apply to agricultural CV fine-tuning. Feature extraction freezes all backbone layers and only trains the detection head - best for very small datasets (under 100 images) or when the target domain is visually similar to the pretraining data. Partial fine-tuning freezes early layers (which capture universal features like edges and textures) and trains the later layers plus the head - the most common approach, balancing generalization with specialization. Full fine-tuning updates all weights, which requires more data (1,000+ images) but yields the highest accuracy when domain shift is severe. Discriminative learning rates - lower rates for early layers, higher rates for later layers - help prevent catastrophic forgetting of useful pretrained features. For teams seeking stronger pretrained representations, DINOv3 (released August 2025, achieving ~66.1 mAP on COCO with frozen features) offers a powerful self-supervised backbone that can reduce the amount of labeled data needed for fine-tuning.
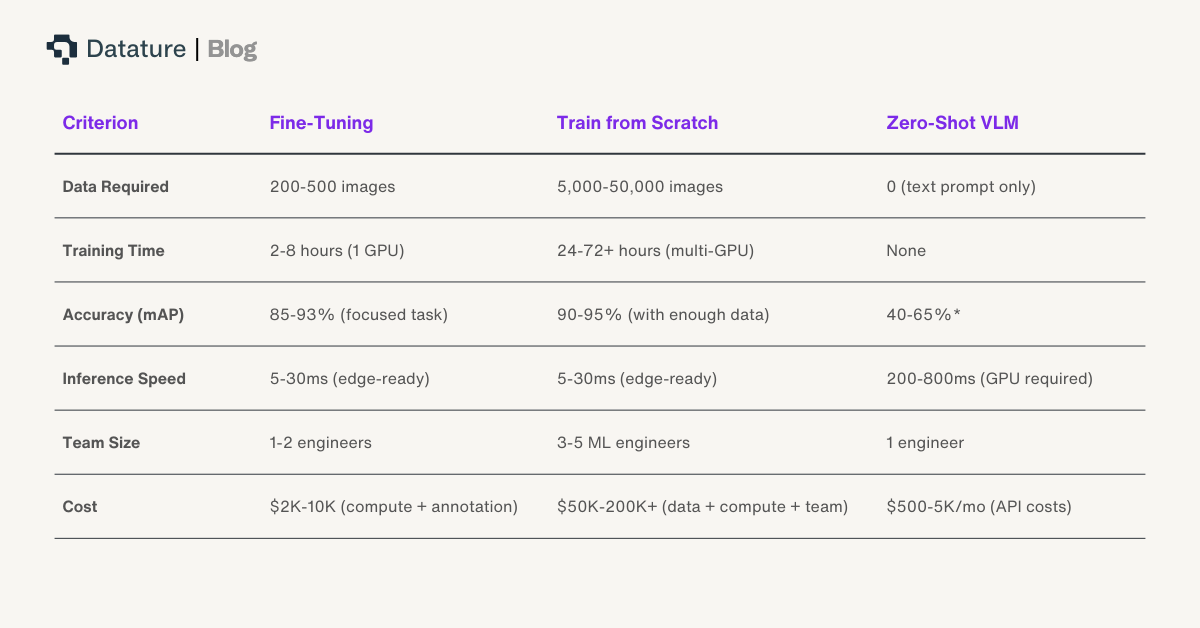
Why VLMs Are Not the Answer for Real-Time (Yet)
Vision-language models like GPT-5.2 and Gemini 3 Pro can identify agricultural objects via text prompts with zero labeled data. But they cannot run on edge hardware. A VLM requiring 16-80GB of GPU memory and 200-800ms per inference does not fit on a Jetson Orin Nano or a Raspberry Pi. VLMs also lack the spatial precision needed for actuation: a weeding robot needs bounding-box-level coordinates at 30+ FPS, not a text description of what the image contains. VLMs are valuable for initial data exploration and annotation bootstrapping - use them to generate candidate labels, then refine with human review and fine-tune a lightweight detector for production.
Annotation Efficiency
Model-assisted labeling and active learning reduce annotation time by 40-60% compared to manual labeling workflows. Start with a small labeled set, train a preliminary model, use it to pre-annotate new images, and focus human effort on correcting mistakes rather than drawing boxes from scratch.
Why Edge Deployment Is Non-Negotiable for Field Robotics
Edge deployment means running the inference model directly on hardware mounted on the robot, vehicle, or field station - not on a remote cloud server. For agricultural robotics, this is not a preference. It is an architectural requirement driven by four constraints that cloud deployment cannot overcome.
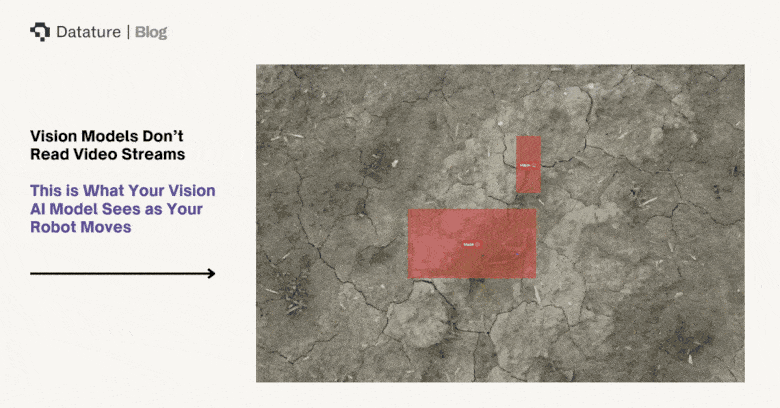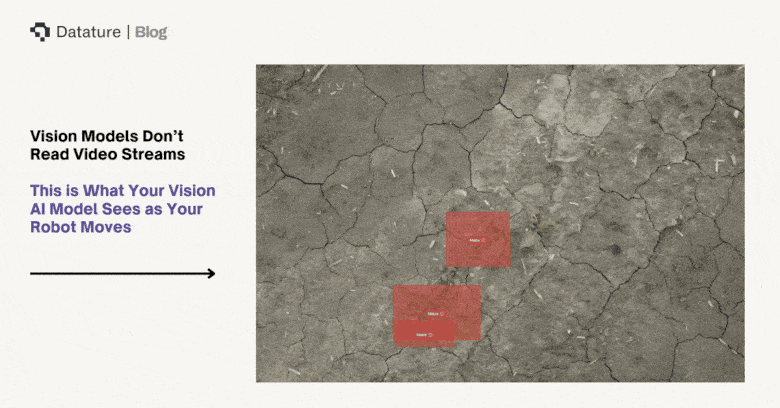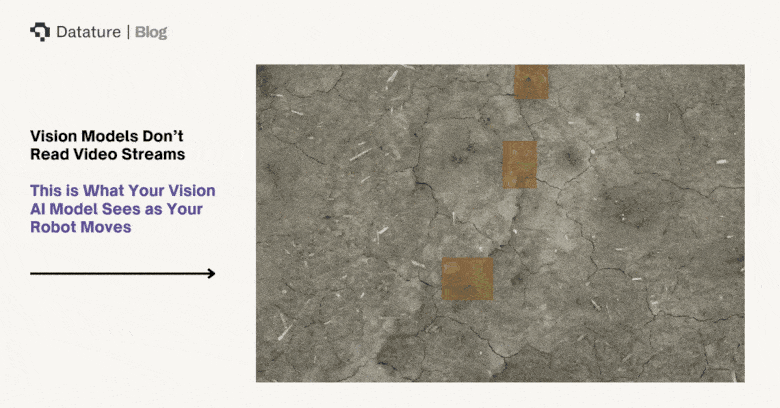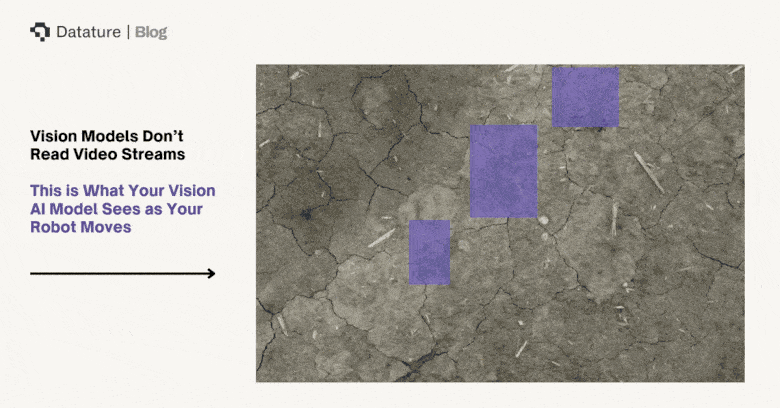
No Connectivity
Agricultural fields typically lack reliable internet access. While greenhouses and indoor farms may have Wi-Fi, open-field operations covering hundreds to thousands of acres rarely have consistent cellular coverage, much less the bandwidth needed for real-time image streaming. FCC broadband maps show persistent rural coverage gaps across the U.S., and similar constraints apply globally. A cloud-dependent architecture fails the moment the tractor drives into a coverage gap - which, in most agricultural settings, is most of the field.
Latency Kills
A weeding robot moving at 3 mph (4.8 km/h) covers approximately 1.3 meters per second. To target a weed with a laser or directed spray, the detection-to-actuation pipeline must complete in under 100ms. Cloud inference round-trip latency - image upload, server processing, result download - ranges from 200-500ms under ideal conditions. Under real field conditions with spotty connectivity, latency spikes to seconds. By the time the cloud response arrives, the robot has moved 0.5-2 meters past the target.
.png)
Bandwidth Cost at Scale
A single RGB camera generating 1080p video at 30 FPS produces 2-15 GB of data per hour depending on compression. A field robot with 4-8 cameras operating 10 hours per day generates 80-1,200 GB daily. Across a fleet of 10 robots, that is 0.8-12 TB per day. At typical cellular data rates, streaming this volume costs $100-840 per day in bandwidth alone - more than the CV system saves in most agricultural applications. Edge processing eliminates this cost entirely by running inference locally and transmitting only results (bounding box coordinates, class labels, confidence scores), which amounts to kilobytes per frame.
Privacy and Data Sovereignty
Farm data is increasingly treated as proprietary intellectual property. Yield data, crop variety performance, disease prevalence patterns, and field-level productivity metrics have direct competitive value. Regulatory frameworks in the EU (GDPR, proposed Farm Data Act) and emerging U.S. state-level agricultural data privacy legislation create compliance requirements for data transmission. Edge processing keeps raw imagery on the device, transmitting only aggregated inference results to the cloud for logging.
.png)
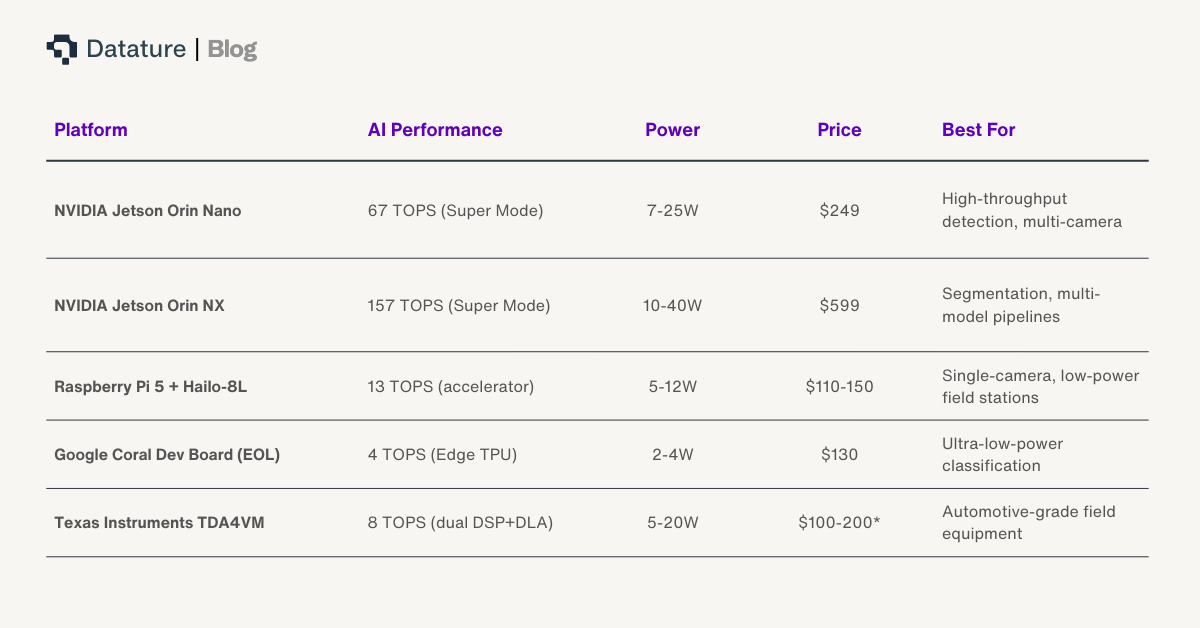
The Hardware Landscape
Edge hardware for agricultural robotics in 2026 spans a range of compute budgets and form factors. The table below covers the most commonly deployed platforms.
Quantization Is Essential
Running a full FP32 model on edge hardware wastes compute and power. FP16 inference is a common first step on Jetson GPUs, delivering 1.5-2x speedup with negligible accuracy loss before committing to INT8. Post-training quantization to INT8 delivers 30-50% latency improvement with typically less than 1% accuracy loss for detection models. For battery-powered robots operating 10+ hour shifts, this translates directly to longer runtime. Combined with model pruning (removing redundant weights), you can often fit a production model into 4-8MB - small enough for microcontroller-class devices.
Edge Deployment Failure Modes
Hardware alone does not guarantee reliable field operation. Common failure modes include: thermal throttling under direct sunlight (Jetson Orin reduces clock speed above 85°C - add passive heatsinks or forced air), model drift as seasons change (retrain quarterly with fresh field data), OTA update failures in low-connectivity environments (implement local fallback models), and camera lens degradation from dust, moisture, and UV exposure (schedule monthly lens cleaning and recalibration).
The Full Pipeline: From Field Data to Deployed Model
Building a production agricultural CV system requires six stages. Each stage has failure modes that can silently degrade the final model. Platforms like Datature Nexus compress this pipeline into a managed workflow where each stage is handled within a single environment, reducing integration overhead and eliminating data format mismatches between tools.
.png)
Step 1: Capture field data. Mount cameras on tractors, drones, or greenhouse fixtures. Collect images across different times of day, weather conditions, and growth stages. A common mistake is capturing all training data in a single session - the model then fails when conditions change. Aim for diversity: morning and afternoon light, wet and dry leaves, early and late growth stages.
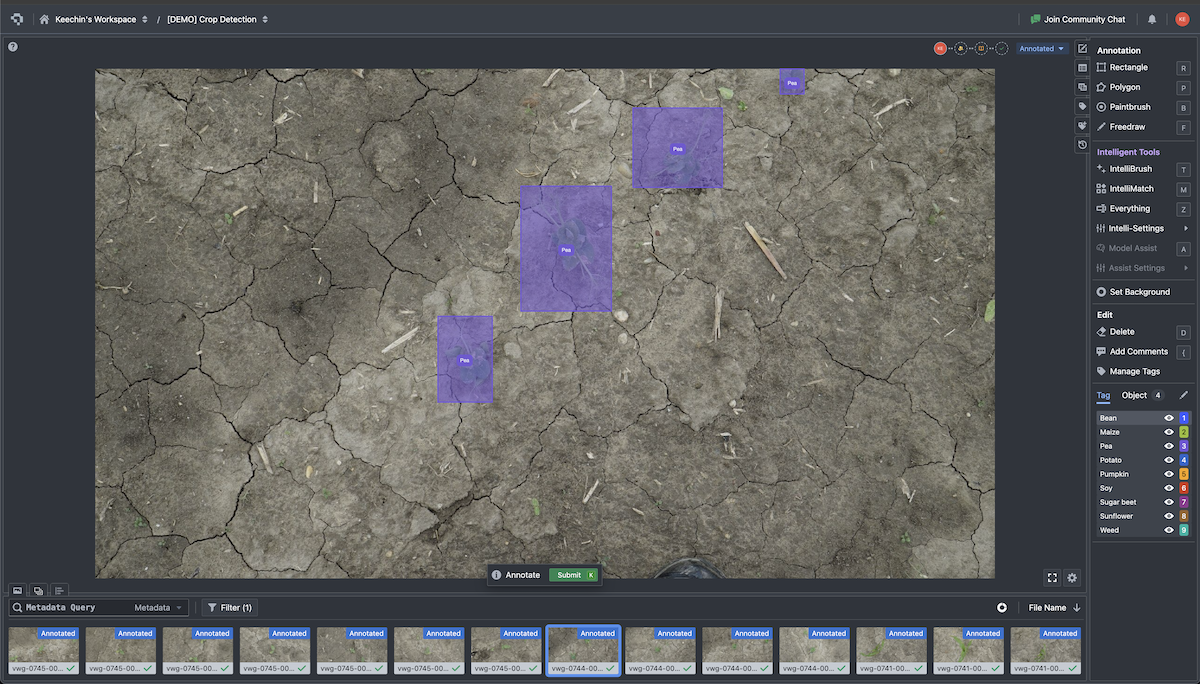
Step 2: Annotate with intelligent tools. Manual bounding-box annotation is slow - 30-60 seconds per image for simple detection tasks. Model-assisted labeling pre-annotates images using a preliminary model, reducing human effort to verification and correction. SAM-assisted annotation generates segmentation masks with a single click. Active learning prioritizes the images that will most improve the model, so you label the 300 most informative images out of 10,000 rather than labeling all 10,000.
Step 3: Train and fine-tune. Select an architecture based on your deployment target. YOLO26-Nano and YOLO26-Small for edge devices with tight compute budgets. EfficientDet or RF-DETR for higher accuracy when GPU power is available. Mask2Former, OneFormer, RF-DETR-Seg (which offers a speed advantage for real-time applications), or DeepLabV3+ when you need pixel-level segmentation masks (e.g., canopy coverage estimation, precise weed boundary mapping). Image augmentation — random rotations, color jitter, mosaic tiling - artificially expands your training set and improves robustness to field variability.
Step 4: Evaluate rigorously. Training graphs reveal whether the model is converging or overfitting. The confusion matrix shows which classes the model confuses - a tomato disease model misclassifying early blight as bacterial spot needs more training data for those specific classes, not more data overall. Per-class mAP identifies underperforming categories before deployment.
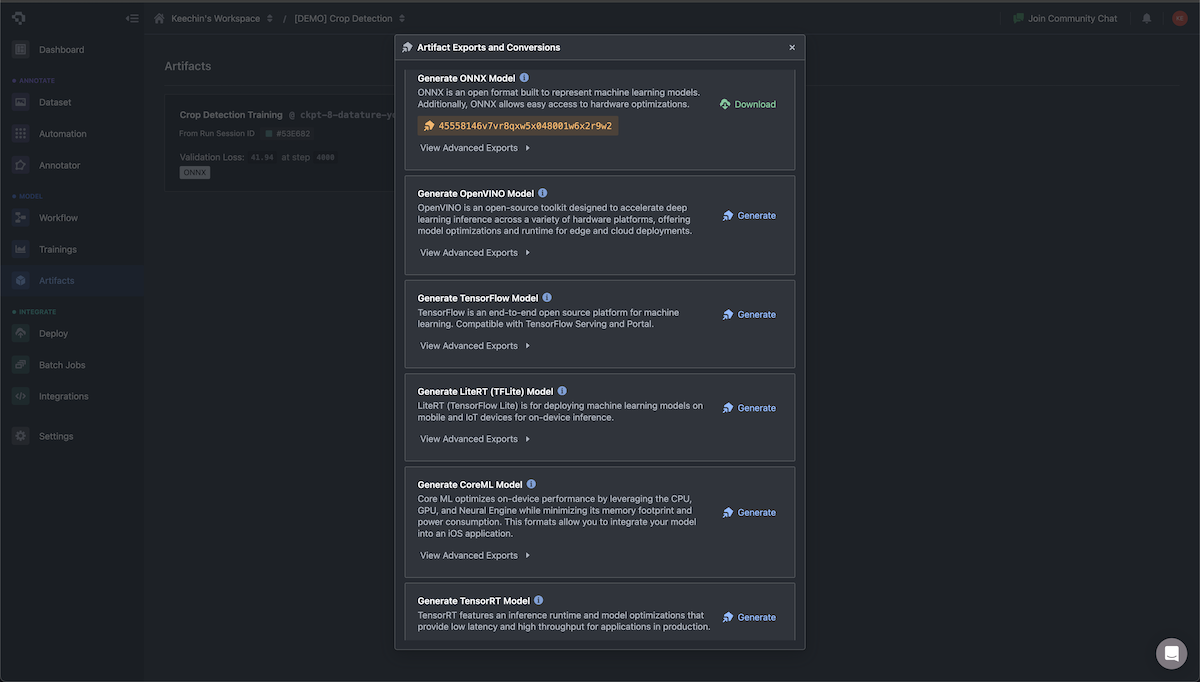
Step 5: Export with quantization. Post-training quantization converts FP32 weights to INT8, cutting model size by 4x and improving inference speed by 30-50% with minimal accuracy loss. Export to the format your hardware requires: ONNX for Jetson, TFLite for Raspberry Pi and Android/LiteRT devices, TensorRT (NVIDIA GPUs only) for maximum GPU throughput.
Step 6: Deploy to edge hardware. Push the quantized model to the target device. Validate inference speed and accuracy on real field imagery (not just held-out test data from the same distribution). Monitor for drift: if accuracy degrades after weeks of deployment, trigger the feedback loop back to Step 2 with fresh field images.
Safety-Critical Considerations
When CV models drive physical actuation - laser weeding, chemical spraying, robotic harvesting - false positives have real costs. A false positive on a weed detector means spraying a crop plant. Set confidence thresholds conservatively (e.g., 0.85+ for spray actuation vs. 0.5 for logging). For high-value crops, implement human-in-the-loop confirmation for detections below the actuation threshold. The cost of a false positive on a $50 melon plant is higher than the cost of missing one weed.
Decision Framework: Build vs. Platform
Every ag-tech company faces this choice: build a custom ML pipeline from scratch, or use an end-to-end platform. The right answer depends on your team, timeline, and deployment complexity. As our Enterprise Vision AI Adoption Report found, most organizations without dedicated ML infrastructure benefit from a platform-first approach.
.png)
Build custom when you have a large ML team (10+ engineers), need proprietary model architectures not available on any platform, require deep integration with custom sensor hardware, or operate at a scale where platform per-seat pricing becomes uneconomical. Use a platform when your priority is speed to production, your team includes domain experts (agronomists, plant pathologists) rather than ML specialists, you are tackling standard detection or segmentation tasks, and you need to iterate quickly across growing seasons.
Most ag-tech companies do not have Google's ML team. A platform approach gets you from field data to a deployed model 5-10x faster. Once you outgrow the platform's capabilities - which happens at significant scale - you will have trained dozens of models and accumulated the domain-specific data that makes a custom pipeline viable.
What Comes Next: The Agriculture CV Roadmap
Agricultural computer vision is evolving along five trajectories that will reshape how field robotics operate over the next 2-3 years.
.png)
Multi-spectral fusion. Combining RGB with near-infrared (NIR), thermal, and hyperspectral imagery enables detection of plant stress 5-10 days before visible symptoms appear. Multi-sensor rigs are already common on agricultural drones; the challenge is calibrating and fusing data from sensors with different resolutions, field-of-view, and spectral bands into a unified input for the model.
Autonomous fleet coordination. Individual robots will give way to coordinated fleets sharing model updates, dividing field coverage, and optimizing routes collaboratively. Federated learning enables model improvement across multiple devices without centralizing raw imagery data - each robot trains locally, shares only gradient updates, and the fleet-level model improves collectively.
Regulatory compliance. The EU AI Act classifies food safety applications as high-risk, requiring audit trails for automated decisions, bias monitoring, and explainability documentation. Agricultural CV systems that trigger spray actuation or grading decisions will increasingly need to log predictions, confidence scores, and model versions for regulatory compliance.
On-device foundation models. Sub-billion parameter models - TinyViT, distilled Grounding DINO, quantized Florence-2 - are beginning to deliver foundation-model capabilities at edge power budgets (5-15W). By 2027-2028, expect agricultural robots to run open-vocabulary detection natively on-device, reducing the need for task-specific fine-tuning for scouting and exploration tasks while still relying on fine-tuned models for high-precision actuation.
Next-generation edge hardware. NVIDIA announced the Jetson T4000 at CES 2026, delivering 1,200 FP4 TFLOPs at a $1,999 price point. While this is above the price range of current agricultural edge devices, it signals that edge compute power is scaling rapidly - capabilities that required cloud GPUs in 2024 will be available at the field edge by 2027-2028.
Frequently Asked Questions
What accuracy can I expect fine-tuning for crop disease detection?
Fine-tuning a YOLO26 or EfficientDet model on 300-500 labeled images of a specific crop disease typically reaches 85-93% mAP, depending on class count and image quality. Single-disease detectors (e.g., only detecting powdery mildew on grape leaves) with clean, well-distributed annotations routinely exceed 90% mAP. Multi-disease detection across 5-10 disease classes usually stabilizes at 80-88% mAP and benefits from image augmentation to handle class imbalance.
How many labeled images do I need for a custom agricultural model?
For a focused single-class detection task (one weed species, one disease), 200-500 well-labeled images are typically sufficient when fine-tuning from a pretrained backbone. Multi-class problems (10+ categories) require 1,000-3,000 images for robust generalization. Use active learning to maximize the value of each labeled image - the platform selects the most informative samples, so you spend annotation time where it matters most.
Can YOLO26 run on a Raspberry Pi for agricultural robotics?
YOLO26-Nano runs at approximately 8 FPS on a Raspberry Pi 5 CPU at 640px input resolution. Adding a Hailo-8L AI Kit accelerator (~$60) brings throughput to roughly 30 FPS, which is sufficient for many agricultural monitoring tasks. For higher-throughput requirements (multi-camera, real-time actuation), NVIDIA Jetson Orin Nano provides 67 TOPS at $249. See our Raspberry Pi deployment guide for a step-by-step walkthrough.
What is the difference between edge and cloud deployment for farm CV?
Edge deployment runs the model directly on hardware mounted on the robot or vehicle, enabling sub-50ms inference with zero internet dependency. Cloud deployment sends images to remote servers, requiring reliable connectivity and adding 200-500ms round-trip latency. For field robotics in areas without consistent cellular coverage - which describes most agricultural land - edge deployment is the only architecturally viable approach. Cloud deployment remains useful for batch processing of drone imagery and model training, where latency is not a constraint.
How does Datature handle agricultural image annotation?
Datature Nexus provides three annotation acceleration tools relevant to agriculture: SAM-assisted annotation generates segmentation masks with a single click, useful for leaf boundary delineation and canopy mapping. Model-assisted pre-labeling uses a preliminary trained model to auto-annotate new images, reducing human effort to verification and correction. Active learning analyzes model uncertainty to prioritize the images that will most improve accuracy, so you label 300 high-value images instead of 3,000 random ones. These tools reduce annotation time by 40-60% compared to manual workflows.
How easy is it to train my own model on my own dataset with Datature?
Very easy. Datature is a complete platform that covers you from data annotation to model training. You can select your deployment parameters, and we recommend different model architecture, quantization and more. Datature also converts models into a wide variety of formats for you so you can integrate with your devices easily.
How do I update my models when my robots are already deployed in the field?
We believe the biggest challenge is updating these models when your robots are out in your customer's fields,with spotty connection - so we developed Datature Outpost which uses MQTT to relay weights from your newly trained models to specific machines out in the field. Our system coordinate this patches and even sends back low-confidence predictions so you can fix your models on edge cases easily and redeploy a patch before your customers use them again - remotely.
Conclusion
Deploying computer vision on agricultural robots requires solving three problems that generic ML pipelines do not address: domain shift from benchmark to field data, environmental variability across seasons and weather, and the latency constraints of real-time actuation on connectivity-limited hardware. Fine-tuning on domain-specific field data closes the accuracy gap. Edge deployment closes the latency and connectivity gap. A managed platform closes the team and timeline gap.
The companies succeeding in agricultural CV are not the ones with the biggest ML teams. They are the ones that identified a focused detection task, annotated a few hundred representative images, fine-tuned a lightweight model, quantized it for their target hardware, and deployed it to the field - then iterated quarterly as conditions changed.
If you are looking to improve your Vision AI models or consider building them - speak with us!
.png)
.png)
