Visual Question Answering (VQA)
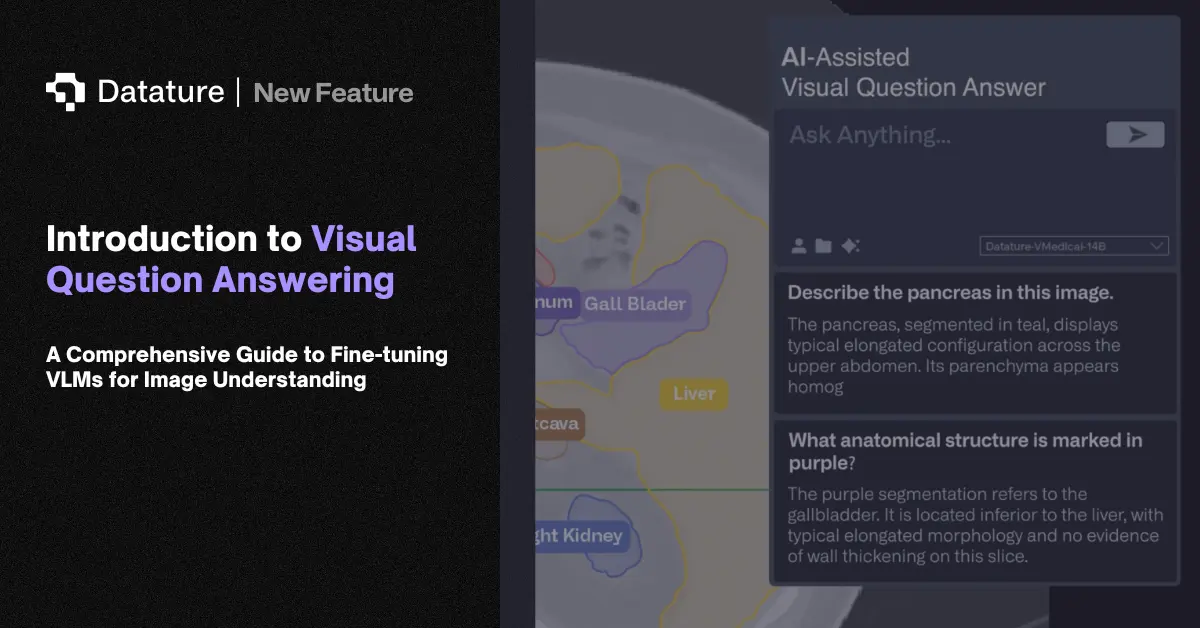
Visual question answering (VQA) takes an image and a natural language question as input and returns a text answer. Here's what that looks like in practice: given a kitchen photo and the question "how many chairs are at the table?", the model locates the table, counts the chairs, and answers "four." Answering correctly requires both visual perception and language reasoning. That combination makes VQA one of the standard benchmarks for vision-language models.
Early VQA systems used separate CNN and LSTM encoders with attention-based fusion. Modern approaches rely on end-to-end VLMs like PaliGemma, Qwen-VL, and LLaVA, where a vision encoder feeds image tokens into a language model that generates the answer. Key benchmarks include VQAv2 (open-ended questions on natural images), TextVQA (questions requiring reading text in images), GQA (compositional reasoning), and DocVQA (document-based questions). Fine-tuning a VLM for domain-specific VQA (answering questions about X-ray images or manufacturing defect reports, for example) requires a few thousand question-answer pairs and parameter-efficient techniques like LoRA.
VQA shows up in accessibility tools, medical imaging, document processing, retail product search, and quality inspection. In each case, the pattern is the same: a user asks a question about an image and gets a text answer without writing code or learning specialized software. Medical teams query diagnostic scans. Quality engineers ask about defect details on production line images. The common thread is that VQA turns visual data into something non-technical users can query through plain language.