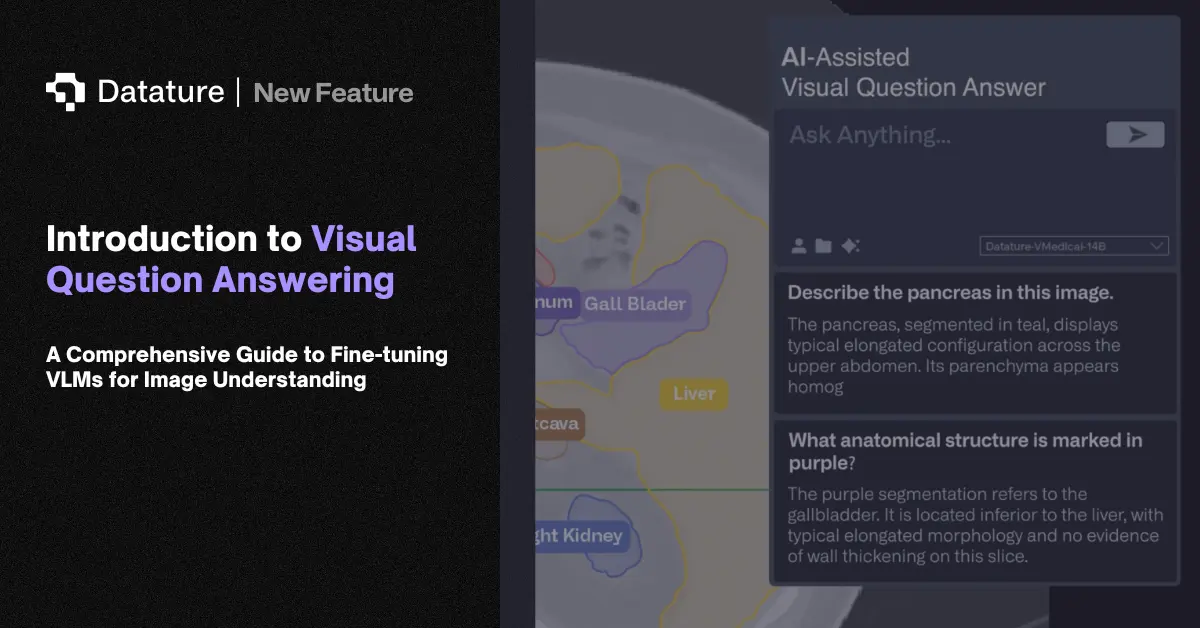
Visual Instruction Tuning
Visual instruction tuning is the process of fine-tuning a VLM on datasets of (image, instruction, response) triplets so the model learns to follow diverse natural language commands about visual content. Rather than training a model for one task (e.g., only captioning or only VQA), visual instruction tuning teaches a single model to handle many tasks: describe this image, how many people are in this photo, what text appears on the sign, is there anything unusual here? A single model handles all of these with one set of weights.
LLaVA pioneered this approach by using GPT-4 to generate instruction-following data from existing image-caption datasets. The pipeline works in three stages: (1) generate diverse question-answer pairs about images using a strong text model and existing captions, (2) pre-train the vision-language connector on image-caption pairs, (3) fine-tune the full model on the instruction-following dataset. Subsequent models (LLaVA-1.5, InternVL, Qwen-VL) refined the data generation process and scaled the instruction datasets to millions of examples covering conversation, detailed description, complex reasoning, and multi-turn dialog.
Visual instruction tuning is what makes modern VLMs useful as general-purpose visual assistants rather than single-task models. Teams adapting VLMs for specific domains (medical, industrial, agricultural) follow the same pattern: create domain-specific instruction datasets, then fine-tune. The quality and diversity of the instruction data matters more than volume. A few thousand well-crafted domain-specific instruction pairs often outperforms generic data 10x the size.