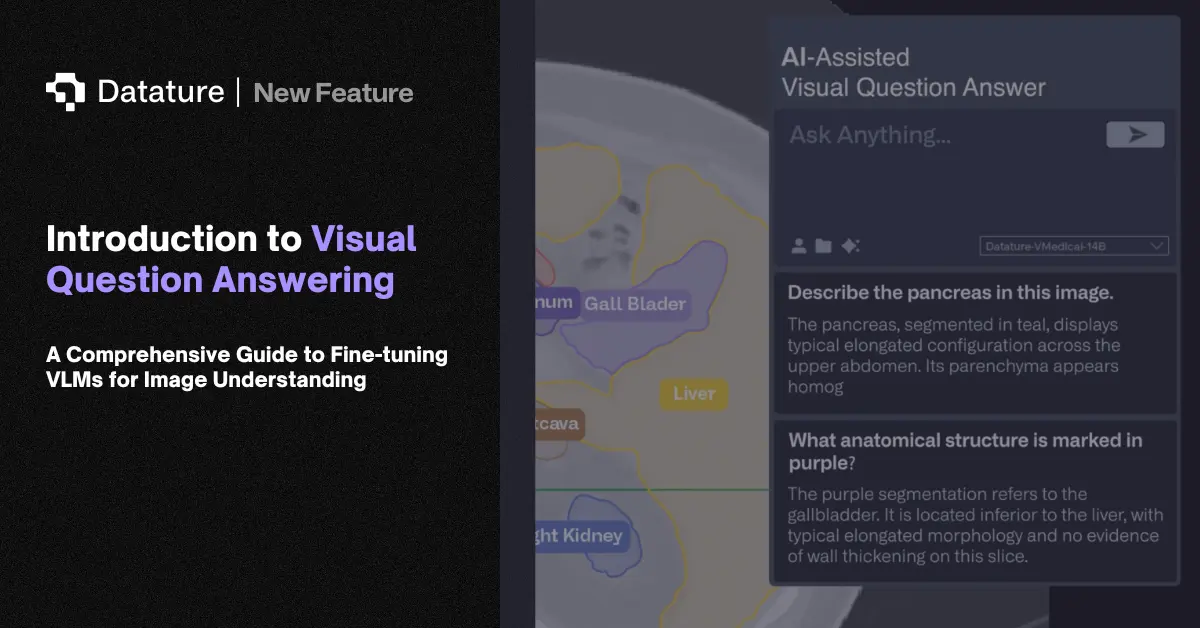
Vision Language Model (VLM)
A vision language model (VLM) is a neural network that takes both images and text as input and produces text, bounding boxes, or other structured outputs. Unlike traditional computer vision models that work with fixed class labels, VLMs understand free-form language. You can ask a VLM to "find all safety violations in this factory image" without training it on a predefined list of violation types. This flexibility makes VLMs useful across domains where defining every possible class upfront is impractical.
Most VLMs share a three-part architecture: a vision encoder (typically a Vision Transformer like ViT or SigLIP) that converts the image into a sequence of patch embeddings, a projection layer that maps these visual tokens into the language model's embedding space, and a large language model (LLM) that reasons over the combined visual and textual tokens. Models like LLaVA, PaliGemma, Qwen-VL, and Florence-2 differ in how they connect these components. Some use simple linear projections, others use cross-attention or Q-Former modules. Fine-tuning a VLM for a specific domain typically uses LoRA or similar parameter-efficient methods to adapt the model without retraining from scratch.
Manufacturing teams use VLMs to describe defects in natural language rather than fixed categories. Medical teams generate preliminary findings from scans, while retailers automate product cataloging from photographs. VLMs also power visual question answering, image captioning, visual grounding, document understanding, and open-vocabulary detection. The shift from fixed-class models to language-driven VLMs is the largest architectural change in computer vision since transformers replaced CNNs.
.png)