Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is an architecture pattern that improves large language models (LLMs) or vision-language models (VLMs) by grounding their responses in retrieved external knowledge rather than relying only on what the model memorized during pre-training. This reduces hallucination and lets the model answer questions about information it was never trained on.
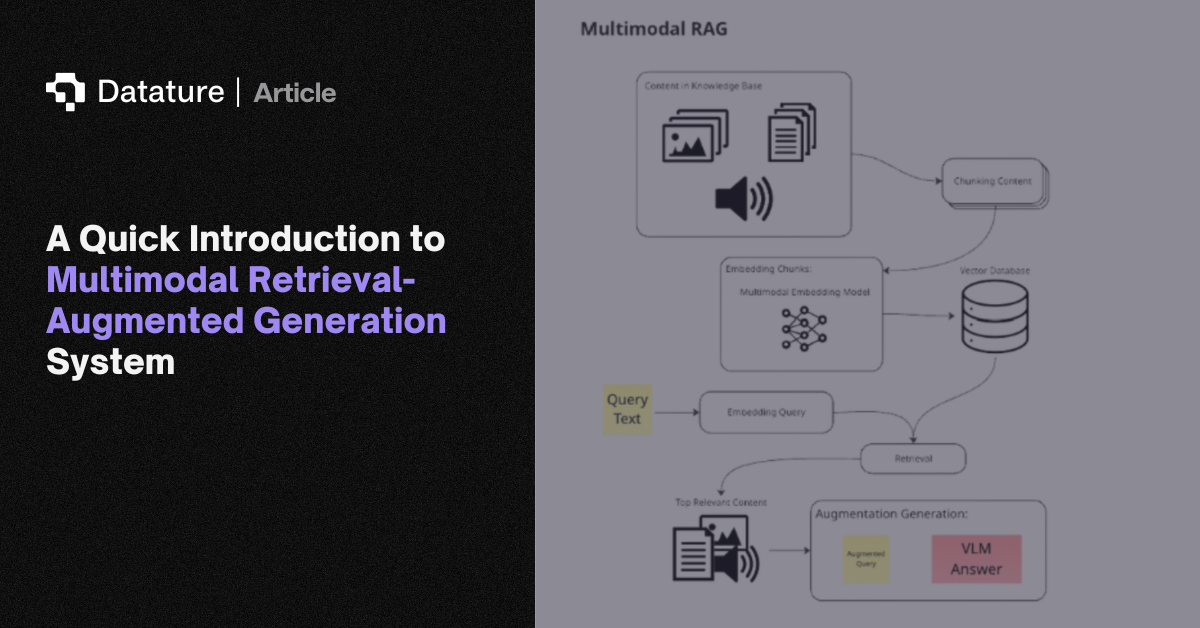
A RAG pipeline has three stages. Indexing: documents, images, or knowledge base entries are split into chunks, converted to vector embeddings (using CLIP for images, text-embedding models for text), and stored in a vector database (Pinecone, Weaviate, Milvus, ChromaDB). Retrieval: given a query, the system finds the most semantically similar chunks via approximate nearest-neighbor search. Generation: the retrieved chunks are injected into the model's context as reference material, and the model generates a response grounded in that evidence.
Multimodal RAG extends this to visual data. Image embeddings, diagram descriptions, and chart data are indexed alongside text, letting VLMs answer questions about images they've never seen during training. This is valuable for enterprise knowledge bases, technical documentation search, and computer vision applications where models need to reference visual catalogs (defect libraries, product databases, medical imaging atlases) without fine-tuning on each new dataset.