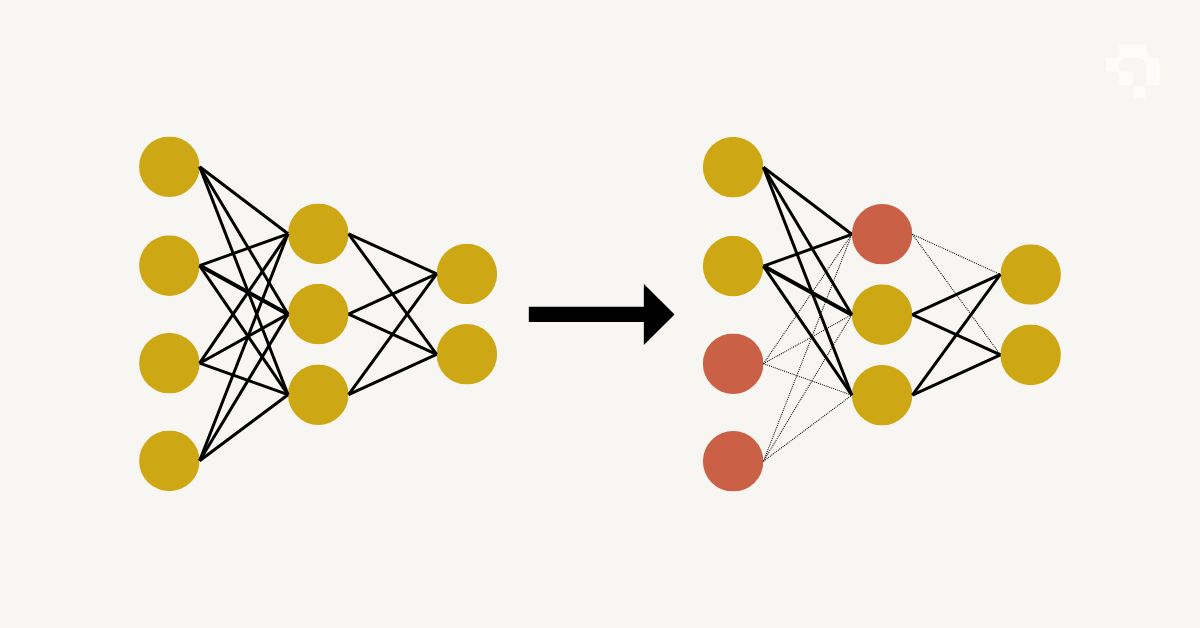
Neural Network
A neural network is a computational model made of layers of connected nodes (neurons) that learn to transform input data into useful outputs through exposure to training examples. Each neuron computes a weighted sum of its inputs, adds a bias term, and passes the result through a non-linear activation function (ReLU, sigmoid, GELU). The weights start random and are adjusted during training via backpropagation and gradient descent.
Architectures vary by task. Fully connected (dense) networks work for tabular data. Convolutional neural networks (CNNs) like ResNet and YOLO apply small learned filters across images to detect spatial patterns. Recurrent networks (LSTMs, GRUs) process sequences. Transformers (ViT, DETR, GPT) use self-attention to model long-range dependencies and have become dominant across both vision and language tasks. Key design choices include depth (number of layers), width (neurons per layer), skip connections (enabling very deep networks), normalization layers (stabilizing training), and dropout (preventing overfitting).
Neural networks are the building block behind virtually all modern computer vision, from simple image classifiers to complex multi-task systems that detect, segment, track, and describe objects simultaneously. Training requires labeled data and GPU compute, but transfer learning and pre-trained models have made neural networks practical even for small teams with limited resources.
.png)