Model Inference
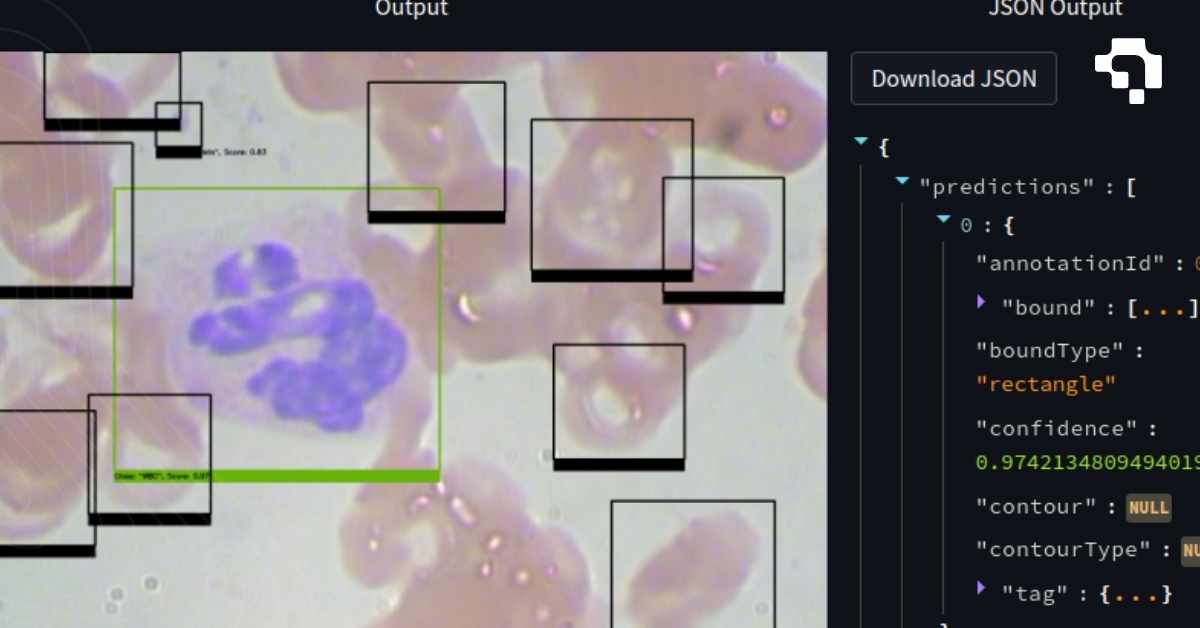
Model inference is the process of running a trained model on new input data to generate predictions. Training is where the model learns; inference is where it puts that learning to use. In computer vision, inference means feeding an image or video frame through the network and getting back bounding boxes, class labels, segmentation masks, keypoints, or embeddings.
Inference performance is measured in latency (milliseconds per image) and throughput (images per second). These depend on model size, input resolution, hardware (CPU vs. GPU vs. dedicated accelerator), batch size, and optimization level. A ResNet-50 classifier might run at 5ms per image on a modern GPU but 200ms on a CPU. YOLO26 achieves real-time detection at 30+ FPS on an NVIDIA Jetson by being designed specifically for fast inference with efficient backbone operations.
Production inference requires more than just running the model. It includes preprocessing (resizing, normalizing, padding inputs to expected format), post-processing (NMS for detection, thresholding for segmentation, decoding model outputs into usable coordinates), batching (grouping multiple inputs for parallel processing on GPU), and serving infrastructure (REST APIs, gRPC endpoints, model version management). Optimization techniques like quantization (INT8 inference), TensorRT compilation, and ONNX Runtime acceleration can deliver 2-5x speedup over naive PyTorch inference. Datature supports inference through its API deployment and Outpost edge deployment features.

.jpg)