


As edge AI adoption increases in popularity, companies need faster, smaller, and more private solutions rather than bulky, inefficient, cloud-dependent setups. We have partnered with MemryX and in this article, we will explore the performance of MemryX’s MX3 M.2 AI Accelerator module, an innovation among edge accelerators, through Datature’s Nexus platform.
About MemryX
MemryX, Inc. (memryx.com) is an AI chip company headquartered in Ann Arbor, Michigan. MemryX focuses on developing AI accelerator chips that offer comparable performance and accuracy at lower power and cost compared to current industry-leading solutions. As a result of their cost and power savings, MemryX solutions are well positioned for Edge AI applications including video security, autonomous driving, robotics, machine vision, and more.
MX3 M.2 Module Specifications and Benefits
MemryX’s MX3 M.2 module is provided in a compact M.2 form factor, delivering up to 24 TFLOPS (6 TFLOPS per MX3 chip) and storing up to 42M 8-bit parameters while consuming only 6 to 8 watts of power. The MX3 M.2 module outperforms solutions with significantly higher TFLOPS numbers, showing drastically higher performing inference speeds while running with significantly less power consumption. For example, the MX3 M.2 module is shown to beat the Nvidia Jetson AGX Orin 64GB in inference speed in this video, despite the Jetson consuming much more power and costing nearly 9 times more. Additionally, if you need more performance, the MX3 M.2 module also supports module concatenation, scaling across modules to act as a single large AI compute accelerator.
Along with hardware, the company aims to radically simplify the typical complexity of integrating AI edge computing in real-world applications. MemryX chips automatically optimize AI models for high performance, eliminating the need for manual tuning or hardware-specific adjustments.. Additionally, MemryX also provides detailed documentation, a Software Developer Kit (SDK) and hundreds of example models and applications on GitHub, so that developers can easily deploy, run, and benchmark their AI models. For more information, please check out MemryX’s Developer Documentation.
Overall, despite the smaller form factor, the optimization strategies of the MX3 M.2 module results in a more performant device at a lower cost. This enables versatile integrations and simplified deployment at the edge. The MX3 module is already being applied in areas such as smart vision, industrial automation, mobility, and healthcare. When developing and deploying Edge AI, MemryX and Datature offer a platform that delivers strong cost efficiency, high performance, and scalability compared to other approaches.
Edge Deployment Use Cases
Besides high performance and efficiency, the MX3 M.2 module is built for edge use cases that require privacy, speed, and efficiency.
Since all inference runs locally, there’s no need to transmit sensitive data to the cloud. In opposition to cloud-powered solutions, this reduces exposure to data breaches, helps meet regulatory standards, and allows for edge processing in facilities with unreliable or no internet connection.
The MXA M.2’s rapid inference speed makes it exceptionally well-suited for real-time applications, where timely and reliable insights are critical. By delivering timely accurate insights, identifying changes allows you to promptly take corrective action, and optimize performance the moment events occur.
The power efficient MX3 M.2 module draws only 6 to 8 watts of power, as opposed to NVIDIA Jetson AGX’s estimated 60 watts. This means MemryX’s solution is ideal for applications such as remote surveillance systems and battery-powered robots and drones, where power-hungry hardware isn't an option.
Introducing Datature’s Solutions
MemryX offers a hardware platform to deploy trained models in edge environments that require the performance, efficiency, and privacy advantages of the MX3 M.2 module. However, MemryX only provides a platform to efficiently run a model. MemryX does not develop models or provide model training services. This is where Datature comes in. We enable users to train their own custom vision models on their data, achieving the accuracy you need for any visual insights for your use case, and empowering a seamless deployment of computer vision models.
Datature is an end-to-end MLOps platform built to simplify and accelerate the development of computer vision solutions. From dataset management and annotation to model training and deployment, users can manage their entire model training pipeline in a single, cloud-based platform that easily integrates into your current stack and infrastructure.
In tandem, Datature and MemryX provide a comprehensive solution that allows you to not only rapidly build custom models from the ground up, but also deploy your solution at the edge with a performant, yet cost-effective solution. Ultimately, this allows you to easily adopt and scale AI solutions in your operations without significant compromise.
Datature’s Solutions on MX3 M.2 Modules
Industrial Dataset and Annotations
This workflow begins with a personal protection equipment object detection dataset, using 3508 images sourced from the PPEs Dataset by Roboflow and licensed under CC BY 4.0. The dataset consists of detections of workplace safety compliances and violations, such as missing goggles, gloves, and protective shoes. To learn more about importing your own data and annotations, or annotating your data on the Datature Platform, please refer to our documentation and tutorials.
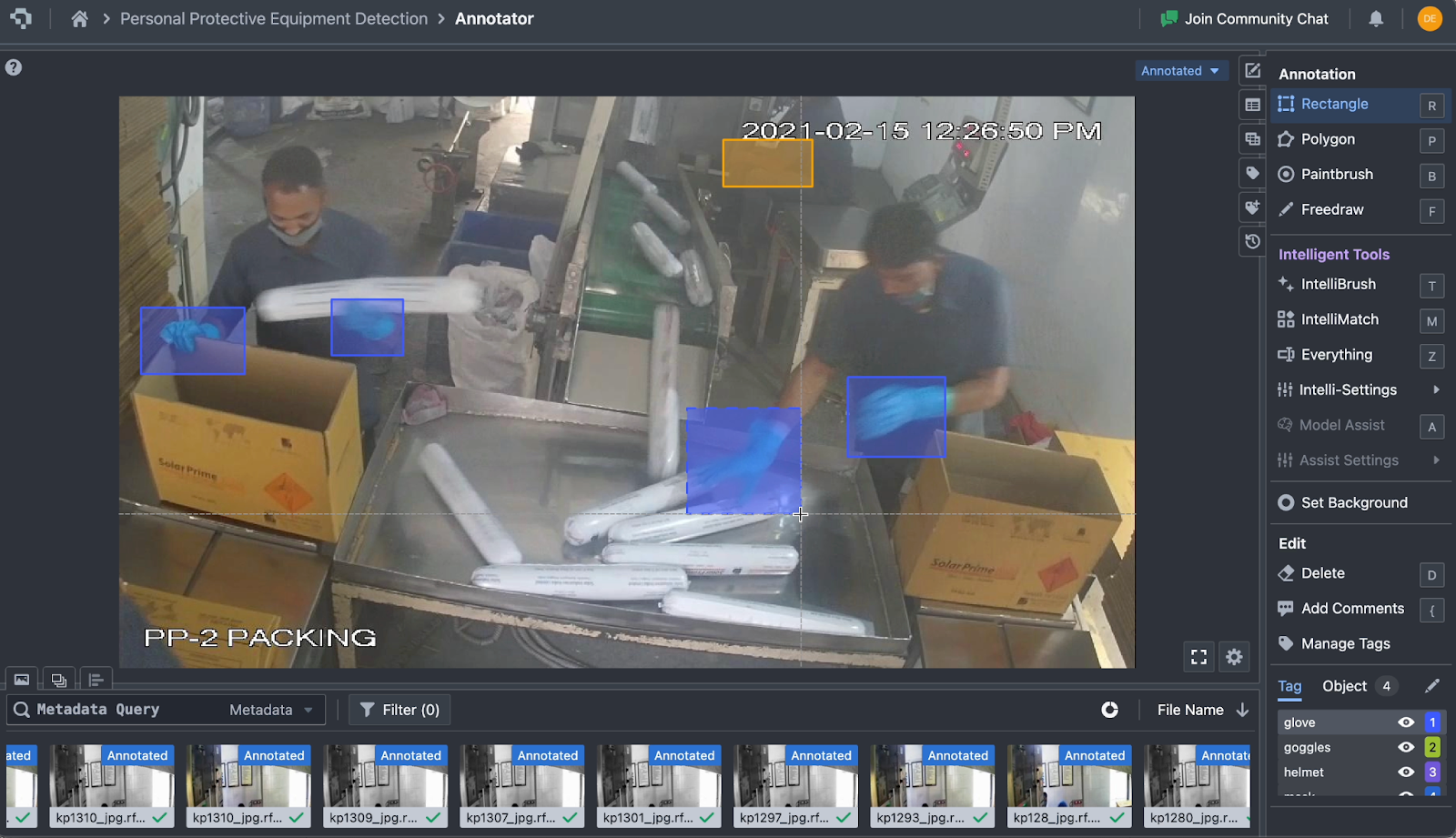
Model Selection
The YOLOv8 Nano model is chosen for this use case as it is small, fast to train, and accurate, perfect for an edge use case with MemryX’s accelerator. The model has been trained and tested on this dataset, evaluating the MemryX's MX3 M.2 module’s inference speed on a realistic industrial application.
Beyond YOLOv8 Nano, Datature offers a diverse catalog of models for training and iteration, allowing users to select the ones that best align with their specific tasks, ranging from lightweight models optimized for edge computing to larger more powerful models.
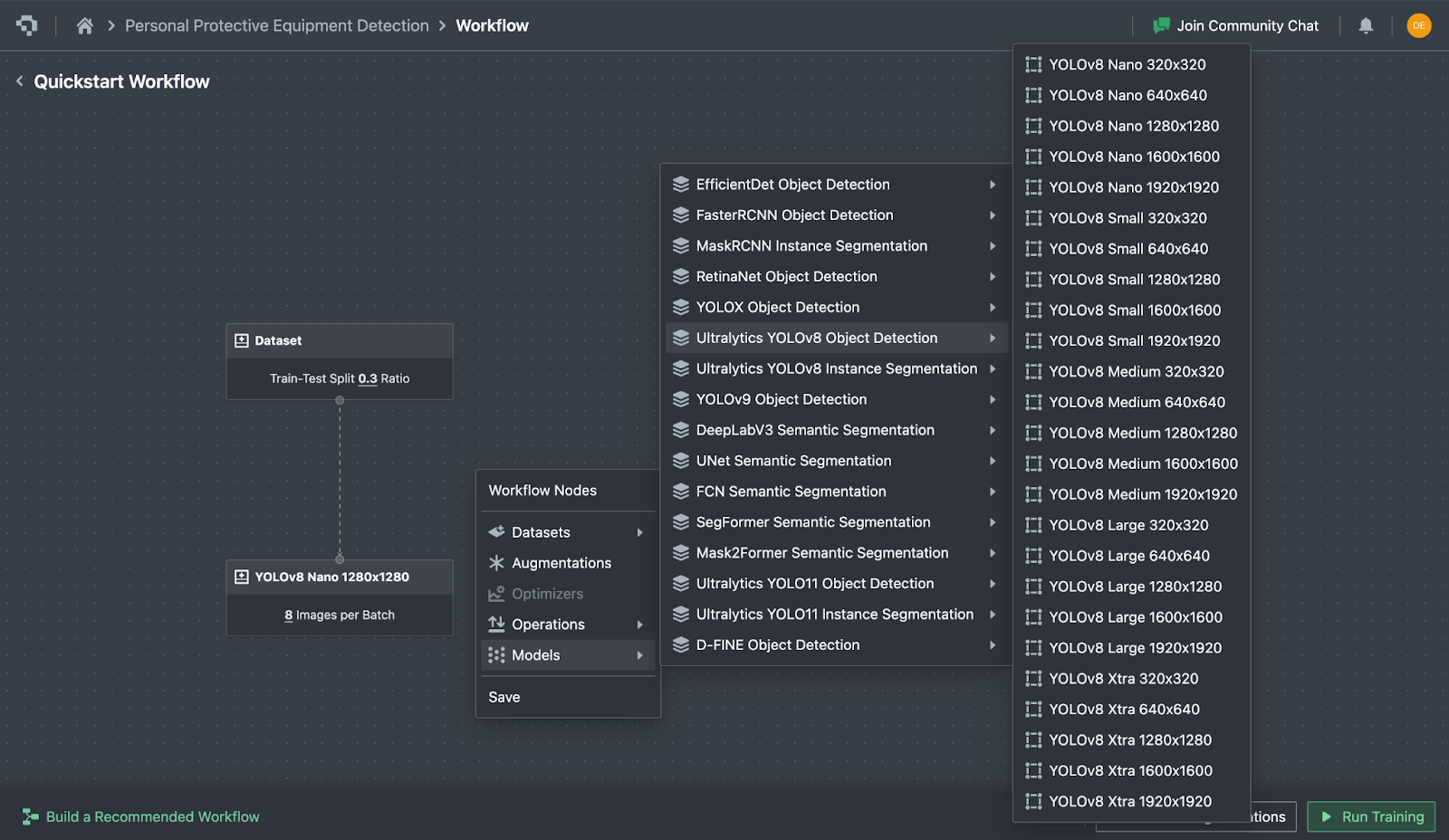
Training Parameters
After the annotation phase, the selected YOLOv8 Nano model begins training through Datature’s fast, iterative model finetuning pipeline. The model is trained using its default pretrained weights, with a batch size of 8 for 5,000 steps on a Nvidia L4 GPU using the Adam optimizer with a learning rate of 0.001.
Datature offers access to a variety of dedicated GPUs to suit different training workloads and performance requirements. Users have the option to train models on Datature’s dedicated GPU infrastructure or use their own local or cloud-based GPU runners.
For an overview of our training capabilities, available GPU options, and model offerings, take a look at our documentation here: Datature Model Training Documentation
Training Results and Export
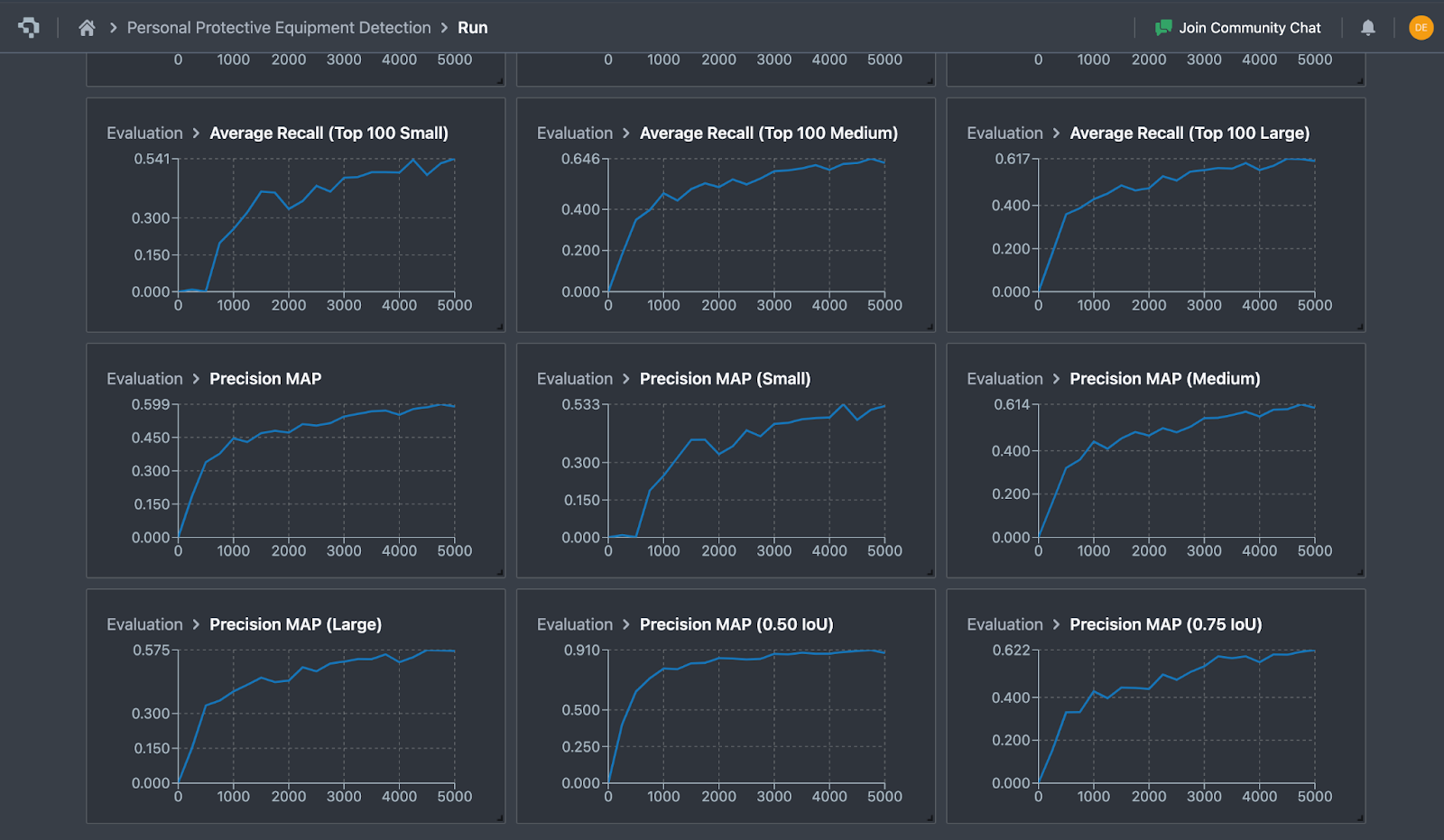
Datature’s platform provides real-time visualization of training and validation metrics for evaluation, supporting iterative model development. After training, the model achieves a strong 0.90 mean average precision (mAP) at an IoU threshold of 0.50 and a mAP of 0.62 at a stricter IoU threshold of 0.75. The metrics show the model is robust in detecting safety equipment compliances and workplace hazards in new images.
Following the completion of training, you can export your trained model through Datature’s Artifacts interface, providing users with a straightforward way to export models, or deploy on the cloud through Datature Cloud. Datature and MemryX both support the ONNX model format, a common industry standard. As such, we export our model in ONNX format and transfer the model to our edge device.
Importantly, all models trained on Datature’s platform remain the user’s own intellectual property, allowing you to deploy at the edge without worrying about unforeseen inference costs. To learn more about deployment options or IP ownership, please reach out to our sales team here.
Model Deployment and Performance
To run the model on MemryX’s MX3 module, the ONNX file describing the model is compiled into a Dataflow Program by MemryX’s Neural Compiler software, which is as straightforward as a CLI command.
mx_nc -m datature-yolov8n.onnx -c 4 --autocrop
After running the command, compiled into the same directory as the ONNX file are .dfp and {your model name} post files, which are used to run the optimized model inference. Shown below are sample output images of protective equipment compliances and violations, indicating robust detections with accurate class assignment.


After benchmarking the model on multiple industrial images, the difference in performance between CPU and MemryX’s MX3 accelerator (labeled MXA in the image) becomes apparent, as the MXA achieves over 18x faster inference speed. (Should include CPU information here)

Conclusion
Coupling Datature’s all-in-one vision AI platform and MemryX’s AI accelerator chips and edge-focused development ecosystem allows users to effortlessly train and deploy AI models at the edge, without compromises in accuracy and efficiency. When developing and deploying Edge AI, MemryX and Datature offer a platform that delivers strong cost efficiency, high performance, and scalability compared to other approaches.
If you have questions about either offering, our teams are ready to discuss how MemryX and Datature can collaborate to develop a tailored solution for your specific use case. Please feel free to reach out to us on our website.
Our Developer’s Roadmap
As the demand for privacy-focused, real-time inference grows, Datature and MemryX are at the forefront of innovative edge AI deployment. Datature is pleased to partner with MemryX to support the growing adoption and advancement of visual edge computing.
If you have questions, feel free to join our Community Slack to post your questions or contact us if you wish to train and deploy your own vision model on Datature Nexus.
For more detailed information about model functionality, customization options, or answers to any common questions you might have, read more on our Developer Portal.
