Image Captioning
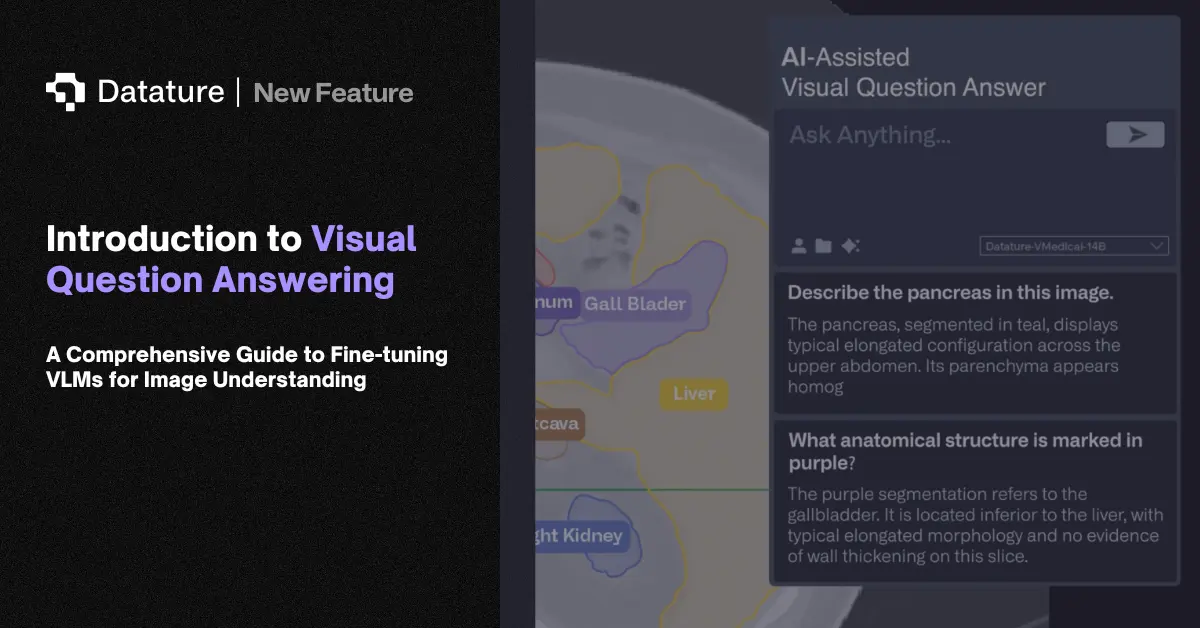
Image captioning generates a natural language sentence describing what's in an image. Given a photo, the model might produce "two people sitting at a table in a restaurant" or "an aerial view of a flooded highway." This is different from classification, which picks from fixed labels, or detection, which draws boxes. Captioning produces free-form text covering objects, actions, relationships, and context.
Modern captioning uses VLMs with an encoder-decoder design: a vision encoder (ViT or SigLIP) extracts visual features, and a language model decoder generates the caption token by token. BLIP-2 introduced the Q-Former to bridge frozen vision and language models efficiently. CoCa combined contrastive and captioning objectives in a single model. PaliGemma, Florence-2, and Qwen-VL all support captioning as a core task. Dense captioning extends this by generating separate captions for multiple regions in the image. Evaluation metrics include CIDEr (consensus with human references), BLEU (n-gram overlap), and METEOR (semantic matching).
Captioning powers several practical workflows: automatic alt-text for web accessibility, visual search engines that index images by description, content moderation, and product catalog generation from photographs. Medical teams use it to draft reports from diagnostic images. For organizations managing thousands of images, automated captioning cuts per-image processing time from minutes to milliseconds.