Data Preprocessing
Data preprocessing covers the steps applied to raw images and annotations before they enter a training pipeline. The goal is to get data into a consistent format that the model expects and to remove noise that could hurt learning. Common operations include resizing images to a fixed resolution, normalizing pixel values (scaling to 0-1 or standardizing with dataset mean/std), converting color spaces (BGR to RGB), and padding images to uniform dimensions for batching.
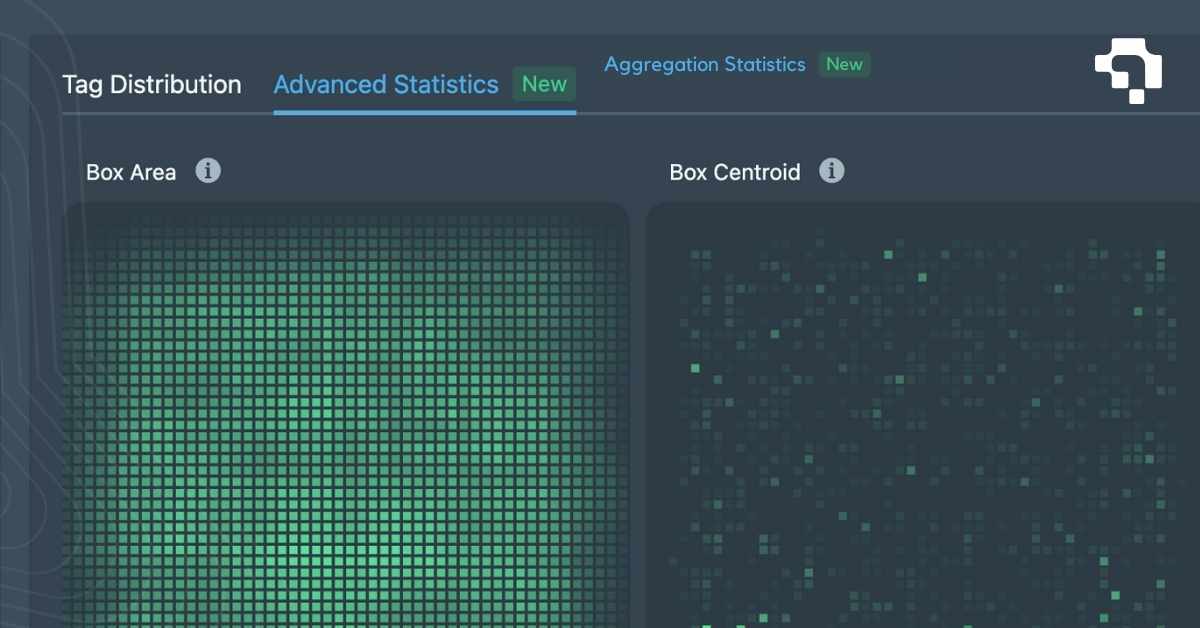
For object detection and segmentation, preprocessing also transforms the labels: bounding box coordinates get rescaled when images are resized, segmentation masks are resampled to match new dimensions, and class mappings are encoded as integer tensors. YOLO models expect a specific letterbox resize that preserves aspect ratio with gray padding. Transformer-based models often use different normalization statistics (ImageNet mean/std vs. dataset-specific values).
Poor preprocessing is a common source of silent bugs. A mismatch between training and inference preprocessing — different resize methods, forgotten normalization, or inconsistent color channel order — can drop model accuracy significantly without any obvious error. Standardizing the preprocessing pipeline and version-controlling it alongside the model is a best practice.
.png)
.jpg)