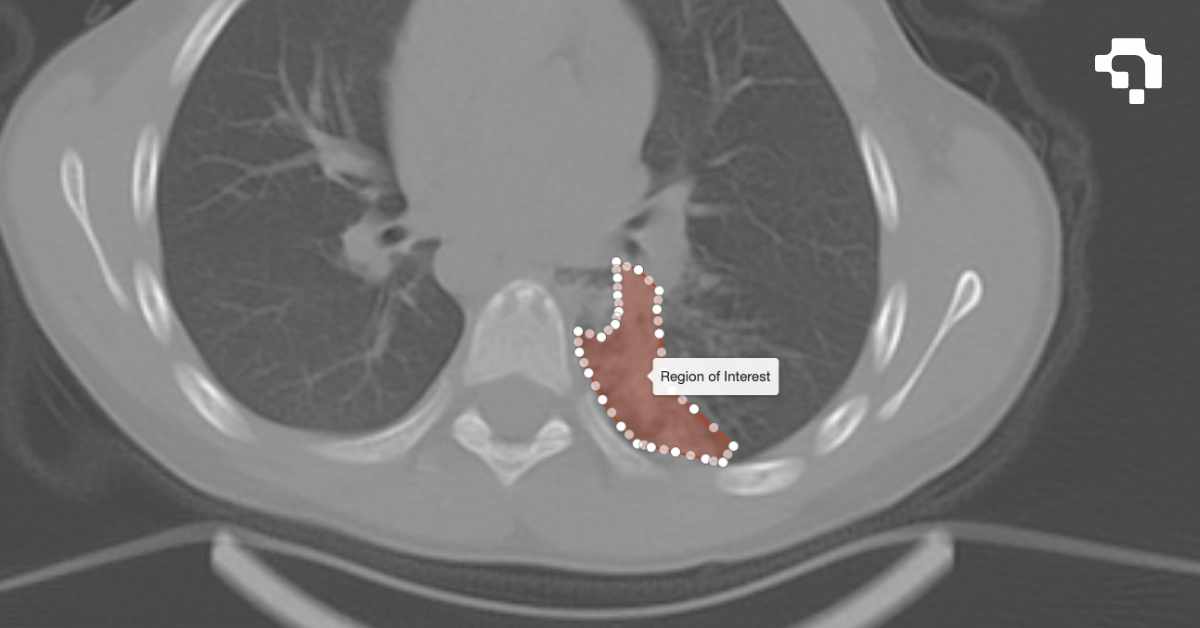
Panoptic Segmentation
Panoptic segmentation assigns every pixel in an image both a semantic class label and an instance identity, combining two previously separate tasks into one unified output. Semantic segmentation labels all pixels (including "stuff" categories like sky, road, and grass) but can't distinguish individual objects. Instance segmentation identifies separate "thing" objects (each car, each person) but ignores background regions. Panoptic segmentation does both: every pixel is labeled, and every countable object gets its own instance ID.
Kirillov et al. introduced the task and the Panoptic Quality (PQ) metric in 2019. PQ jointly measures recognition quality (did the model identify the right class?) and segmentation quality (how well does the predicted mask overlap with ground truth?). Early methods ran separate semantic and instance pipelines and merged results (Panoptic FPN, UPSNet). Modern architectures like Mask2Former and kMaX-DeepLab use a single transformer decoder with learnable queries to predict all segments in one pass, eliminating the need for separate pipelines and post-hoc merging.
Panoptic segmentation is valuable for autonomous driving (understanding drivable surface plus individual vehicles and pedestrians), robotics (full scene understanding for navigation and manipulation), and medical imaging (segmenting different tissue types while distinguishing individual lesions). It represents the most complete form of pixel-level scene understanding.