Model Pruning
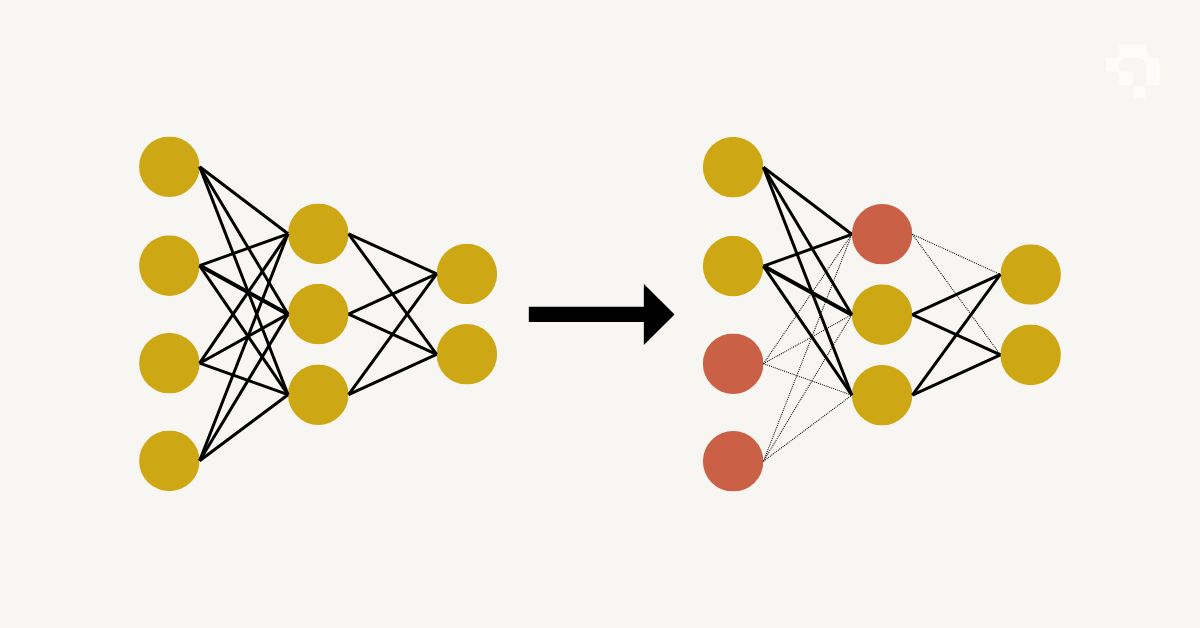
Model pruning removes unnecessary weights or entire structural units (neurons, channels, attention heads, layers) from a trained neural network to make it smaller and faster without significant accuracy loss. The core observation is that neural networks are typically over-parameterized: many weights end up near zero after training and contribute little to the model's predictions. Removing them reduces computation and memory footprint.
Unstructured pruning zeroes out individual weights based on magnitude (smallest weights first) or gradient-based importance scores, producing sparse weight matrices. This achieves high compression ratios (90%+ weights removed) but requires specialized sparse matrix hardware or libraries to see actual speedups. Structured pruning removes entire channels, filters, or layers, which directly reduces the computational graph and speeds up inference on standard hardware without special support. The lottery ticket hypothesis (Frankle & Carlin, 2019) showed that dense networks contain sparse subnetworks ("winning tickets") that can train to full accuracy independently.
A typical workflow trains a full-size model, applies pruning criteria, then fine-tunes the pruned model for a few epochs to recover any lost accuracy. Iterative pruning (prune a little, fine-tune, repeat) often outperforms one-shot pruning. Combined with quantization and distillation, pruning is one of the three main tools for deploying large models on resource-constrained hardware.