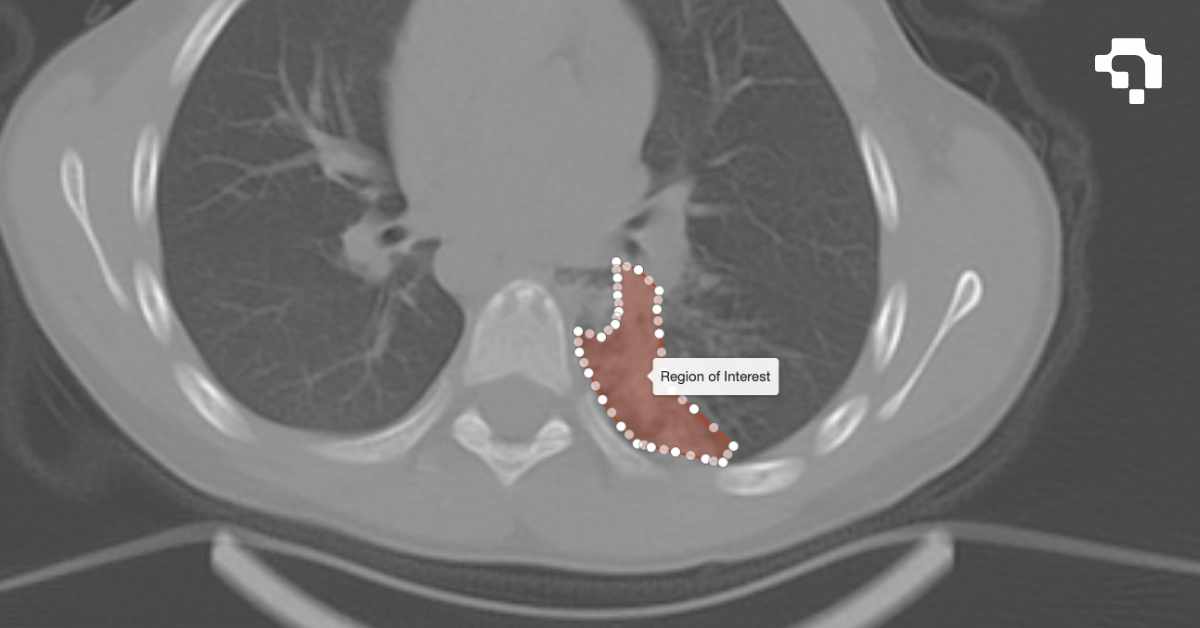
Instance Segmentation
Instance segmentation combines object detection and semantic segmentation into a single task: it identifies every object in an image, classifies each one, and produces a pixel-level mask for each individual instance. Unlike semantic segmentation (which labels every pixel by class but does not distinguish between separate objects of the same class), instance segmentation tells you that there are three dogs in the image and gives you a separate mask for each one.
The most well-known architecture is Mask R-CNN, which extends the Faster R-CNN detector by adding a mask prediction branch that outputs a binary mask for each detected object. More recent approaches include YOLACT (real-time instance segmentation), SOLOv2 (location-based mask prediction without detection), and Mask2Former (transformer-based, handles instance, semantic, and panoptic segmentation in a unified framework). SAM (Segment Anything Model) can also produce instance-level masks when given point or box prompts.
Instance segmentation is used when you need precise object boundaries, not just bounding boxes. Applications include autonomous driving (separating individual pedestrians and vehicles for path planning), medical imaging (delineating individual cells or tumors), robotics (grasping specific objects), and industrial inspection (measuring the exact shape of detected defects). The trade-off compared to detection is higher computational cost and the need for more detailed annotations during training.