.png)
.png)

SAM 3: A Technical Deep Dive into Meta's Next-Generation Segmentation Model
Meta AI has released Segment Anything Model 3 (SAM 3), a fundamental architectural evolution from its predecessors that transforms segmentation from a purely geometric task into a concept-level vision foundation model. SAM 3 introduces Promptable Concept Segmentation (PCS), enabling users to segment all instances of visual concepts using text phrase prompts and image exemplars. This represents not merely an incremental improvement but a paradigmatic shift in how visual segmentation tasks can be tackled. Separately, SAM 3 also maintains and improves performance across previous Promptable Visual Segmentation methods (PVS) for image and video modalities, adds new ways for users to provide manual input, and successfully creates novel complex workflows through SAM 3 Agent and multimodal large language models (MLLMs) to target broader task scopes.
What’s Changed With SAM 3?
Promptable Visual Segmentation vs. Promptable Concept Segmentation
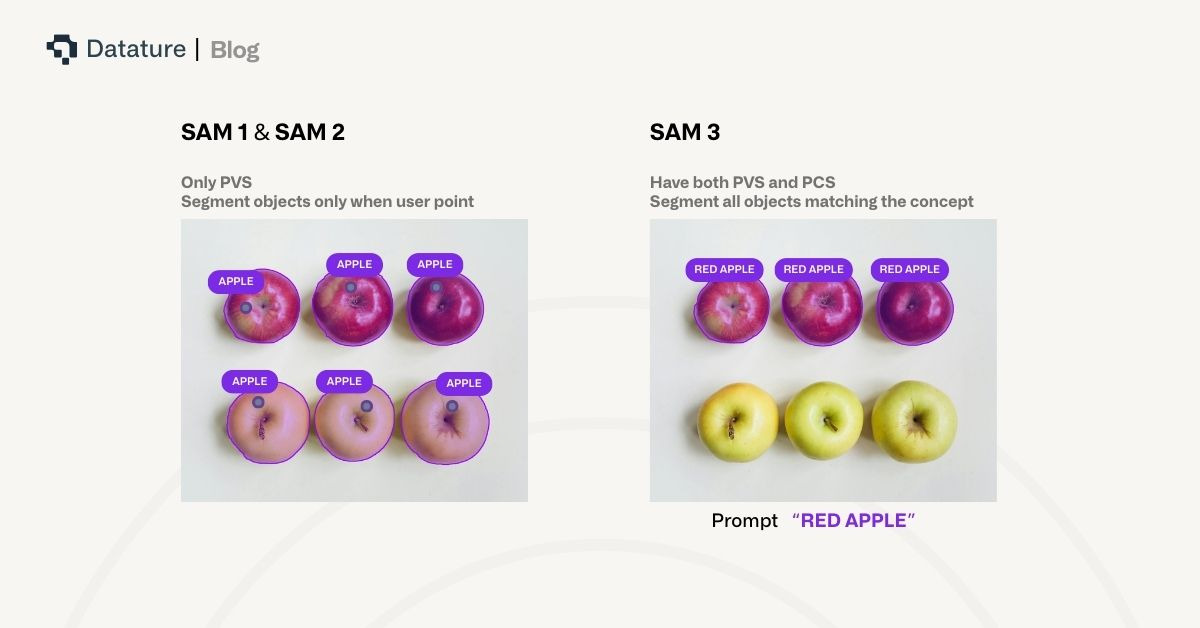
To understand SAM 3’s primary novel contribution of text-based prompting, we should examine how its new task formulations differ from its predecessors. SAM 1 and 2 were designed for Promptable Visual Segmentation (PVS), where users provided geometric prompts such as points, bounding boxes, or masks to segment a single object per prompt. The model excelled at understanding spatial relationships and boundaries, producing high-quality masks for the specific object indicated by the prompt, and developed a strong out-of-the-box visual understanding of objects.
However, with the emergence of large language models (LLMs) allowing people to interact with models through natural language, there is an increasing need for vision models to comprehend text and other modalities in order to interact more easily with users broadly and even LLM agents.
SAM 3 introduces a fundamentally new capability through Promptable Concept Segmentation (PCS). When a user provides a noun phrase like "shipping container”, the model performs open-vocabulary instance detection, returning unique segmentation masks and unique identifiers for all matching objects in the scene simultaneously. This requires the model to first comprehend the phrase, connect that understanding to abstract visual concepts, distinguish between different instances of the same concept, and maintain those distinctions across video frames.
The task definition is currently constrained to short noun phrases consisting of a noun and optional modifiers, such as "red apple" or "striped cat." As such, the model has been primarily trained to focus on recognizing atomic visual concepts, leaving more complex referring expressions that require multi-step reasoning within the MLLM domain, and certainly for further exploration. Though the textual complexity is relatively low, mastering this task subset still demonstrates strong text and vision understanding as it can still be an intrinsically ambiguous task. Multiple valid interpretations can exist for a given phrase due to polysemy (mouse as a device vs. animal), subjective descriptors (cozy, large), vague or context-dependent phrases, boundary ambiguity (whether a person’s outfit includes their bag), and other latent complexities.
Architectural Innovations and Design Philosophy
SAM 3 implements a dual encoder-decoder transformer architecture with approximately 840 million parameters, distributed as roughly 450 million in the vision encoder, 300 million in the text encoder, and 100 million across the detector and tracker components. At present, SAM 3 only has one set of weights, totalling 3.5 GB, which is significantly larger than SAM 2’s largest model which is around 900 MB. This highlights an overall increase in complexity in the architecture, partially increased by an additional text encoder for the new modality, but also by the entire process itself, in order to achieve satisfactory outcomes. We highlight the primary changes below.

Perception Encoder Backbone
Perhaps the most significant architectural change is SAM 3's adoption of the Perception Encoder (PE) as its vision and text backbone. SAM 2 used a Masked Autoencoder (MAE) pre-trained Hiera vision encoder to improve upon localization and visual contextual understanding using multi-level hierarchies to improve understanding at several granularities. However, this approach is not easily compatible with text understanding, and a more flexible architecture was developed.
The Perception Encoder (PE) was pre-trained using contrastive vision-language training on 5.4 billion image-text pairs across multiple vision-tasks. Perception Encoder’s pre-trained backbone is then leveraged to construct two aligned new encoders: PE Language encoder and PE Spatial encoder.
The vision encoder uses a mixture of windowed attention and global attention with Rotary Position Embeddings (RoPE) to enable better handling of position information across different scales and resolutions. The text encoder is causal with a very short context length of 32 tokens. This paired vision-language pre-training provides SAM 3 with broad concept coverage and robustness across diverse visual domains, including the ability to handle domain shifts that would challenge a purely visual model.
After the vision and text are independently encoded, SAM 3 employs a fusion encoder that conditions visual features on the prompt tokens, consisting of self-attention and cross-attention layers and a multi-layer perceptron. This fusion mechanism allows the model to modulate its visual representations based on the semantic concept being queried rather than just concatenate the two embeddings.
Presence Head: Decoupling Recognition and Localization
In order to reduce hallucination issues which would be more prevalent given increasingly vague and indirect user inputs, SAM 3 introduced a learned global presence token and corresponding presence head. In DETR-based architectures like those used in SAM 2 and state-of-the-art object detection models, object queries simultaneously perform recognition and localization. This forces queries to maintain both global awareness and local precision, creating an optimization conflict.
The presence head solves this through factorization by decomposing p(query matches concept) into two components: p(query matches concept | concept is present in image) multiplied by p(concept is present in image). The presence token is a learned embedding solely responsible for global recognition that outputs a single presence score shared across all object queries but excluded from Divide-and-Conquer DETR (DAC-DETR) supervision.
Each individual object query now only needs to determine that given that we know the concept exists somewhere in the image, whether this particular query is a match. The final score for each detection is the product of the query score and the shared presence score.
Detector Architecture
The detector follows the general DETR paradigm with vanilla attention mechanisms, and has a maximum of 200 objects detected. The mask head is adapted from MaskFormer and includes a semantic segmentation head that predicts a binary label for every pixel in the image based on prompts.
During training, SAM 3 adopts dual supervision from DAC-DETR and the Align loss. The DAC-DETR approach helps with training stability and convergence by dividing queries into groups and applying different supervision strategies. The Align loss improves the alignment between predicted boxes and masks by ensuring consistency between these two representations of the same object.
Image Exemplars and Interactive Refinement
Beyond text prompts, SAM 3 supports image exemplars provided as bounding boxes with associated binary labels (positive or negative). This new interaction demonstrates the PCS task capability entirely within the vision space by prompting the model to provide other examples of the image exemplar within the rest of the image.

Each image exemplar is encoded by a dedicated exemplar encoder that combines three sources of information: a positional embedding for the box location, a label embedding indicating whether it's positive or negative, and ROI-pooled visual features from within the bounding box. These elements are concatenated and processed by a small transformer to produce exemplar tokens. These tokens are optionally concatenated with text tokens to form the complete prompt representation that guides the fusion encoder.
Video Architecture and Tracking Integration
For video understanding, SAM 3 inherits the transformer-based cross-attention memory bank architecture from SAM 2, but SAM 3 introduces tighter coupling between detector and tracker through the shared PE backbone. The tracker includes a prompt encoder, mask decoder, memory encoder, and memory bank that encodes the object's appearance using features from past frames and frames where the object was first detected or user-prompted.

The tracker still scales linearly with the number of objects, so deployment is still fundamentally limited by the number of objects required for tracking.
Temporal Disambiguation Strategies
SAM 3 addresses the object ambiguity issues that SAM 2 had with four main postprocessing strategies, inspired by historical tracking approaches adapted for previous SAMs.

First, the model maintains a score based on the number of past frames where it was successfully matched to a detection. If a masklet's detection score falls below a threshold, it is suppressed to reduce false tracks.
Second, SAM 3 implements periodic re-prompting where high-confidence detection masks are used to re-initialize the tracker, replacing the tracker's own predictions to ensure recent and reliable references in the memory bank.
Third, a track confirmation delay mechanism validates candidate masklets over a temporal window, requiring the masklet to appear throughout the window to be valid, to reduce ID switching and the impact of anomalous detections.
Fourth, detection-guided re-prompting is used to fix tracker predictions that drift from the true object boundaries based on IoU.
SAM 3’s New Dataset: SA-Co
SAM 3's performance breakthrough is at least in part, driven by Segment Anything with Concepts (SA-Co) dataset. This dataset represents the largest concept-segmentation corpus to date, comprising approximately 5.2 million high-quality images with 52.5K videos, over 4 million unique noun phrases, approximately 1.4 billion masks across all subsets, and a 22.4 million node ontology.
The data engine evolved through four phases, each progressively increasing the use of AI models to funnel human effort toward the most challenging failure cases and expanding visual domain coverage.

Phase 1 established a foundational image set through human verification with images sourced from previous datasets with automatic annotation from other models. Phase 2 introduced AI verifiers fine-tuned from Llama 3.2 models to determine which images required human validation as well as provide captioning annotations, doubling the data engine’s output, with AI verifiers matching human verifiers in accuracy. Phase 3 focused on scaling and domain expansion, broadening SA-Co/HQ coverage ranging from medical and aerial imagery to wildlife scenes, as well as previously underperforming use cases: crowded scenes with high object counts and images with very small objects. Phase 4 extended the data engine to video, focusing on challenging single-shot clips lasting 5-30 seconds with crowded objects and tracking failures.
Training Methodology and Stages
SAM 3's training also occurred in four stages, matching the four stages of dataset collection. Stage 1 was Perception Encoder pre-training, which trained the image and text encoders using contrastive vision-language learning aiming for robust concept coverage and a well aligned embedding space. Stage 2 was detector pre-training, which trained the image-level detector along with fine-tuning of the vision and text encoders. Stage 3 was detector fine-tuning with the highest-quality human-annotated data and an increased number of interactive steps. Stage 4 focused on object tracking. By freezing the PE backbone, it focused exclusively on spatial-temporal tracking without degrading the strong spatial grounding achieved in previous stages.
The SA-Co Benchmark and Evaluation Metrics
To properly evaluate open-vocabulary concept segmentation, the paper introduces the SA-Co/Gold evaluation benchmark which contains a wide variety of subdomains ranging from crowded areas, complex text and object pairs, and fine-grained sport items, with 50x more novel concepts than the previous most robust dataset, LVIS.
Novel Evaluation Metrics
Traditional Average Precision (AP) breaks down for open-vocabulary detection in which tens of thousands of label classes can appear just once. Moreover, AP is easily biased if their confidence scores are not calibrated to represent the model’s actual accuracy.
SAM 3 introduces classification-gated F1 (cgF1) as the primary metric, computed as 100 × pmF1 × IL_MCC. The positive micro F1 (pmF1) measures localization quality only on positive data points with at least one ground truth mask. For each prediction-ground truth pair, optimal bipartite matching is computed based on IoU. The micro F1 aggregates these counts across all positive samples and averages across thresholds.
The image-level Matthews Correlation Coefficient (IL_MCC) measures pure binary classification capability. MCC ranges from -1 to +1, with +1 indicating perfect prediction, 0 indicating random performance, and negative values indicating anti-correlation. Unlike simpler metrics, MCC accounts for class imbalance and is informative even with heavily skewed negative ratios.
For video, phrase-based HOTA (pHOTA) adapts the Higher Order Tracking Accuracy metric to open-vocabulary prompts by treating each video-noun phrase pair as a unique category. This measures both detection accuracy (pDetA) and association accuracy (pAssA), providing insight into whether failures come from missing objects or identity switches.
Experimental Results and Performance Analysis
The experimental evaluation of SAM 3 spans multiple dimensions: image concept segmentation with text, video concept segmentation, visual exemplar prompting, few-shot adaptation, object counting, traditional VOS tasks, and interactive segmentation.
Unsurprisingly, in the image concept segmentation category, SAM 3 demonstrates its state-of-the-art robustness across a broad range of dataset types.
The few-shot adaptation experiments reveal SAM 3's strong visual adaptation capabilities when provided with task-specific training data. Across multiple datasets, SAM 3 demonstrates its superiority in zero-shot and few-shot contexts. We note below only categories with well-established competitive models to offer a fairer comparison of performance, like visual exemplar prompting, traditional object tracking, and interactive segmentation.
Visual Exemplar Prompting
When prompted with a single visual exemplar (a random ground truth box), SAM 3 substantially outperforms T-Rex2. On COCO with text+image prompting, SAM 3 achieves 78.1 AP+ (evaluated only on positives) versus T-Rex2's 58.5. On LVIS, the margin is 78.4 versus 65.8. On ODinW13, SAM 3 reaches 81.8 AP+ compared to 61.8 for T-Rex2. Notably, SAM 3 performs better with combined text and image prompts than with either modality alone, demonstrating that text removes ambiguity about what concept the visual exemplar represents.

Video Object Segmentation
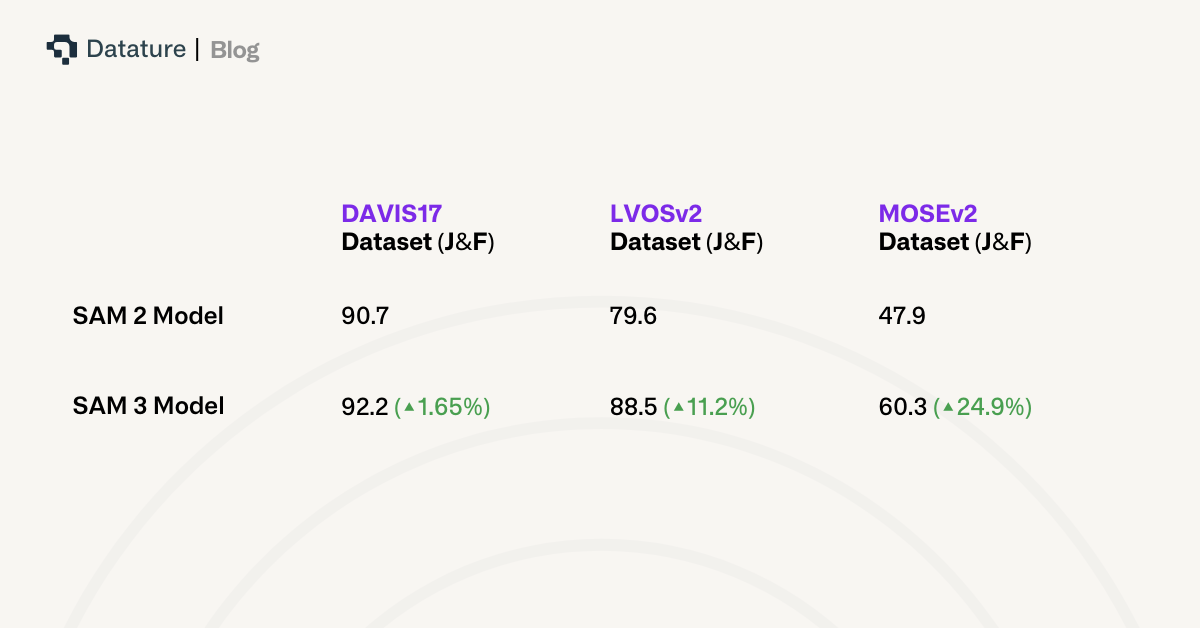
Despite adding concept-level capabilities, SAM 3 improves over SAM 2 on traditional tasks. On Video Object Segmentation benchmarks, SAM 3 achieves 92.2 J&F on DAVIS17 versus 90.7 for SAM 2.1, 88.5 versus 79.6 on LVOSv2, 83.5 versus 77.9 on SA-V validation, and critically 60.3 versus 47.9 on the challenging MOSEv2 dataset—a 12.4 point improvement.
Interactive Segmentation
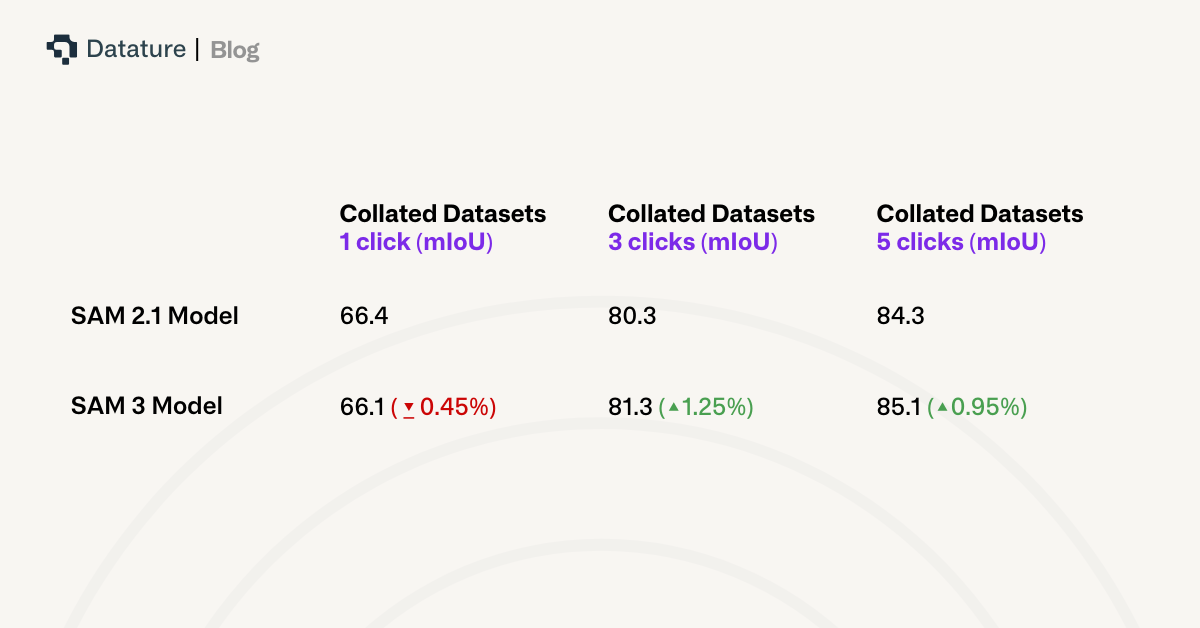
On interactive image segmentation across 37 datasets, SAM 3 achieves 66.1 average mIoU with 1 click, 81.3 with 3 clicks, and 85.1 with 5 clicks, compared to SAM 2.1's 66.4, 80.3, and 84.3 respectively.
Ablation Study
Presence Head
The presence head provides a 1.5 cgF1 improvement, with the gain primarily in IL_MCC (0.82 versus 0.77), confirming its role in decoupling recognition from localization. The paper also examines supervision strategies, finding that supervising mask scores only when the concept is present (rather than negatively supervising all queries for negatives) works best with the presence token architecture.
Hard Negatives
Hard negatives prove critical for open-vocabulary performance. Models trained without hard negatives achieve just 0.44 IL_MCC compared to 0.68 with 30 hard negatives per image, while maintaining similar pmF1. This demonstrates that hard negatives primarily improve the model's ability to reject visually similar but incorrect concepts rather than improving localization quality.
Vision Backbone
The choice of vision backbone substantially impacts performance. PE-L+ achieves 43.2 cgF1 on SA-Co/Gold compared to 35.3 for DINOv2-L and 32.8 for Hiera-L. Moreover, PE achieves 42.5 COCO-O AP compared to 31.9 for DINOv2 and 22.0 for Hiera, demonstrating superior robustness to domain shifts. Using PE's aligned text encoder provides further gains over using PE vision with an unaligned DistilRoBERTa text encoder (43.2 versus 38.1 cgF1).
Training data ablations reveal complementary benefits of different data sources. SA-Co/EXT alone achieves 23.7 cgF1. Adding SA-Co/SYN improves this to 32.8, and adding SA-Co/HQ reaches 45.5, with the full combination achieving 47.4. Detailed scaling laws show that both SA-Co/HQ and SA-Co/SYN continue improving performance with increasing data scale, with SA-Co/HQ providing particularly strong gains on in-domain evaluation and fine-grained concepts, indicating substantial room for future improvement by scaling synthetic data and model size.
Domain Adaptation
When adapting to the held-out food and drink domain, the finetuned model showed similar performance curves as training data scaled, with synthetic data slightly lagging behind human annotation quality, demonstrating strong capability for adaptation.
SAM 3 Agent: Extending to Complex Language Queries
While SAM 3 itself is constrained to simple noun phrases, the paper introduces SAM 3 Agent, which combines SAM 3 with a Multimodal LLM to handle complex language queries requiring reasoning. The agent operates through a perception-action loop: the MLLM analyzes the image, devises a plan, invokes SAM 3 to generate masks using simple noun phrases, inspects the results, and iteratively refines until satisfied.
The agent has access to four tools: segment_phrase (calls SAM 3 with a noun phrase), examine_each_mask (renders masks individually to inspect small or overlapping masks), select_masks_and_return (finalizes the output), and report_no_mask (indicates no matching objects exist). After each intermediate tool call, the MLLM receives the updated image with masks rendered in a Set-of-Marks style plus a text message describing changes.
The system implements aggressive context engineering to handle long reasoning traces. All intermediate trial-and-error states between the initial query and the most recent segment_phrase call are pruned, with only a list of previously-tried phrases maintained as memory. While this setup certainly has its limitations, it has potential for greater unity and capability and should definitely be an active area of exploration.
Computational Profile and Practical Considerations
SAM 3 achieves state of the art performance with a model size comparable to SAM 1, but still multitudes larger than SAM 2. From the SAM 3 paper, On an H200 GPU, SAM 3 processes a single image with 100+ detected objects in approximately 30 milliseconds. For video, inference latency scales with the number of objects being tracked, sustaining near real-time performance (30 FPS) for approximately 5 concurrent objects. To support real-time inference on videos with more objects, the inference can be parallelized across multiple GPUs: up to 10 objects on 2 H200s, up to 28 objects on 4 H200s, and up to 64 objects on 8 H200s.
In our experience, the repository still lacks full diligent care in terms of memory usage, and with a 4070 Ti, we were only able to annotate approximately 100 frames before running out of memory for tracking, and inference latency is more akin to SAM 1 than SAM 2. Understandably, significant architectural changes have been made that would necessarily require greater latency, but we can certainly say that accuracy and capability is by far the biggest improvement in SAM 3 whereas latency and compute requirements have either stayed equal or moved in the opposite direction.
Limitations and Future Directions
Despite its significant advances, SAM 3 has several important limitations that present opportunities for future research. The model struggles to generalize zero-shot to fine-grained out-of-domain concepts, particularly in niche visual domains like specialized medical imaging. However, the paper demonstrates that SAM 3 can quickly adapt to new concepts and domains when fine-tuned on small amounts of data, and that domain-specific synthetic data generated by the data engine can improve performance without human annotation.
The constraint to simple noun phrases means SAM 3 cannot directly handle multi-attribute queries or longer referring expressions, though the SAM 3 Agent work shows these capabilities can be added through integration with MLLMs. The video architecture's linear scaling with object count creates computational challenges for scenes with many objects, though parallelization provides a practical solution. The current architecture lacks shared object-level contextual information across multiple tracked objects, which could help resolve ambiguities in crowded scenes.
The hard mode-switch between concept-level and instance-level interactivity means users cannot seamlessly interleave these interaction types in a single session. Future work could explore more fluid transitions between PCS and PVS modes. Additionally, while the presence head decouples recognition and localization, there may be opportunities to further separate detection and tracking objectives or to introduce shared global memory across multiple objects for improved video understanding.
Conclusion
SAM 3 represents a fundamental evolution in foundational vision models, transforming the task beyond visual and geometric cues to concept-level visual understanding. The introduction of open-vocabulary text prompts, the architectural innovations, and the new dataset collectively enable capabilities that were impossible in SAM 1 and SAM 2. We look forward to the incredible potential that lies in deeper integrations with richer text inputs and other modalities, as well as exploration to see how seamless and impactful more complex workflows like SAM 3 Agent can be in pushing the boundaries of multimodal understanding.
Our Developer’s Roadmap
SAM 3 has been integrated into our Nexus platform, powering Intellibrush as the default point-and-click model, as well as our Video Tracking tool to accelerate your labelling workflows. You can simply create a free account to try out how SAM 3 performs on your own custom datasets.
.png)
.png)
