

What is Multiple Object Tracking (MOT)?
Object Tracking is a branch of computer vision which deals with sequences of images and video streams. It can be considered as an extension to Object Detection whereby one or many objects are detected in a sequence of images. In Multiple Object Tracking (MOT), instance IDs are assigned to different objects such that the same object has a consistent unique IDs throughout the video sequence. Common applications of MOT include autonomous driving, camera surveillance, robotics, etc.

1. Algorithms and Models
The general approach to perform Multi Object Tracking involves two stages. The first stage is an Object Detection stage which identifies the location and categories of interested classes inside video frames followed by assigning a unique instance ID to the objects. The object detector uses common Object Detection frameworks such as Faster Region-based Convolutional Neural Network (R-CNN) or YOLO (You Only Look Once).
The second stage is the Instance Association stage which combines the temporal information across different frames to generate a trajectory for each individual object. The primary objective of instance association is to consistently assign Instance ID to objects such that the same objects have the same instance IDs throughout the video sequence. There are two main approaches for instance association. The first approach utilizes motion cues to assign detection boxes to tracklets. This typically involves applying Kalman filter to predict the current frame bounding boxes of monitored tracklets and match detected bounding boxes to predicted bounding boxes based on Intersection-Over-Union similarity metric. Some common implementations of instance association based on IOU score are SORT and BYTETrack.
The second tracking approach utilizes feature information inside bounding boxes to match instances across frames. This usually requires an additional Neural Network to extract features, which will be used to match the content of detected boxes and content of tracklets using a distance metric (e.g. Cosine similarity). As the matching algorithm does not rely on bounding boxes’ locations, this is beneficial in cases where there are big frame-to-frame changes or objects' temporary disappearance. Examples of algorithms using feature matching are DeepSORT, QDTrack. Many implementations combine both motion cues and feature cues to improve tracking performance.

Matching between detection boxes and tracklets is commonly performed by the Hungarian algorithm. For more details about Object Tracking algorithms, refer to our blog article here.

2. Challenges for Multiple Object Tracking
Despite the numerous advancements made in recent years, based on the approach used, there still exist noteworthy limitations. Depending on the information used for instance matching, ID switching may happen. For example, IOU-based associations usually perform poorly when there are drastic frame-to-frame changes or when the video frame-rate is low as the displacement between bounding boxes of the same object instance is high. Another limitation of association using IOU is that once an object is lost, it cannot be recovered if it reappears again in the video. Association based on features helps mitigate these limitations. However, association purely based on content inside the bounding box may be problematic if the appearance of the object changes significantly (occlusion) as the model interprets the object as a new instance and initiates a new tracklet.

For Multiple Categories Object Tracking, many algorithms perform instance association for prediction boxes independently within the same class. If misclassification occurs for an object, it may be assigned more than one class which leads to multiple instance IDs in a video sequence. The misclassification problem is apparent for datasets with a large number of classes, with several classes having very similar features or many rare classes with limited training data. To address the class switching problem, a common approach is class-agnostic detection whereby class outputs from object detection models are ignored during association step and instance matching is performed based on motion and feature cues without assignment of class priors. However, the removal of class assignment before association means that the number of matching pairs is significantly higher and many False Positives predictions.
Track Every Thing in the Wild
Track Every Thing in the Wild is a paper published by Siyuan Li et al. (2022) that proposes new methods to address the aforementioned challenges. The paper makes three main contributions:
- Introduce a new evaluation metric which independently evaluates three different aspects of Multiple Object Tracking: localization, classification and association, making evaluation of Object Tracking more meaningful.
- Decouple localization and classification during object detection step. Object detection step is class agnostic and does not assign any hard classification to Regions of Interest (ROI). This means during association, objects are allowed to match with all objects from previous frames.
- A Class Exemplar Encoder network is trained to extract class-related features for prediction boxes. The purpose of CEM embeddings is to group objects with similar class-related features together before instance association. Class Exemplar Matching (CEM) helps improve tracking performance compared to pure class agnostic methods.
These contributions push for a novel perspective in solving the multiple object tracking task, while making concrete improvements upon previous state-of-the-art papers.
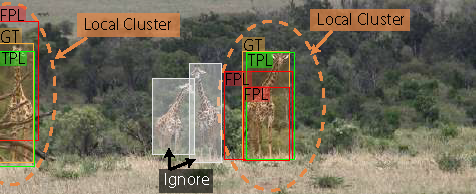
1. Test EveryThing Accuracy (TETA) metric
TETA Accuracy independently measures three components: localization score, classification score and association score. Separating the evaluation metric into different components helps to understand different aspects of the tracker. For example, in scenarios where class labels are not critical, we may want to focus evaluation mainly on localization and association performance. To avoid needing to exhaustively annotate every object and too many False Positives, the authors limit evaluation to local clusters of predictions with IOU with ground truth bounding boxes exceeding a threshold. False Positives which do not belong to any clusters are not evaluated.
2. Test EveryThing Tracker (TETer) Model
The overall architecture of TETer can be seen from Figure 6. The multistep object tracking algorithm first starts with Class Agnostic Localization whereby Region of Interests (ROIs) are generated. The ROIs then go through Class Exemplar Encoder which extracts class-relevant features and produces embeddings for soft object classification (Class Exemplar matching where the objects from next frames are matched with objects from previous frames). The grouped outputs from Class Exemplar Matching (CEM) represent the different soft categories based on similarities between the objects' extracted features. The Instance ID is then assigned during the Instance Association step, which produces the tracks for individual objects.

3. Associate-Every-Thing (AET) strategy with Class Exemplar Matching
Generally MOT methods perform object detection tasks followed by object association to assign a trajectory to a sequence of images. This involves assigning hard categories to proposed regions of interest (ROI) or bounding boxes, which are then used in the second stage of association usually within the objects of the same class. With real-world datasets containing a large number of classes, the classification task of sequence of images poses a challenge whereby classification performance on rare classes is poor but the tracker can still track the presence of the object inside the image sequence.

Instead of using a hard class label as prior segregation between classes, TETer uses a soft labeling approach Class Exemplar embedding to classify a region of interest (ROI). Instead of assigning class labels using using Softmax classifier and argmax function, the soft class embeddings are learned with a Class Exemplar Network, and association of objects is done by comparing the Class Exemplars of ROIs between different frames using similarity comparison matrix (e.g. Cosine similarity). The soft score allows more fine-grain feature matching when comparing between categories and reduces the impact of misclassification.
4. Temporal Class Correction Utilizing Class Exemplar Score
Based on the Class Exemplar, incorrect class label assignment in certain frames can be corrected if predictions belong to the same track despite having different classification labels. Instead of assigning a class to each frame, the tracker remembers classification of an object instance from the last 10 frames and simply outputs the class with the highest frequency using majority voting.

Model Training
1. Model Architecture
The architecture of Track EveryThing Tracker (TETer) is described below in three main components: the object detector, the loss function used to train the model, and the exposed hyperparameters that can be tweaked based on the use case.
Object Detector
- Region Proposal Network that uses Faster R-CNN with ResNet Backbone and Feature Pyramid Network (FPN) for generating class agnostic bounding box predictions.
- Class Exemplar Encoder is a feature-extraction module consisting of several Convolutional Neural Network (CNN) layers followed by several fully connected layers. The output is the Class Exemplar embeddings to use for matching between ROIs. The embeddings are trained to extract high-level features representing similar classes

- Quasi-Dense Embedded Module to be used for instance association using quasi-dense similarity learning (Quasi-Dense Similarity Learning) with Group Normalization. The network is trained to learn the low-level embeddings which differentiate object instances of the same class.
Tracker
This module is designed to initialize new tracks and perform instance association based on quasi-dense embeddings and Temporal Class Correction using Class Exemplar scores. The tracker initiates new tracks on prediction boxes with prediction scores above a certain threshold. Prediction boxes are matched with existing tracklets by the Hungarian algorithm which maximizes the overall instance similarity of QD embeddings.

2. Loss Functions
- L2 Loss: This loss is focused on training Region Proposal Network (RPN) to generate class-agnostic bounding boxes. The usage of L2 loss for bounding boxes is fairly standard for determining differences between box locations.
- Unbiased Supervised Contrastive Loss: For training Class Exemplar Encoder network. Basically it measures how similar CE embeddings of Positive Samples are to Ground Truth boxes. Measure of similarity used is Cosine similarity.
- Bidirectional Softmax: This is used to train the Quasi-Dense Embedded Head.
3. Hyperparameters Settings
Some important hyperparameters affecting tracking performance:
- IOU Margin (Cluster Assignment): Minimum threshold for assigning prediction boxes to a local cluster. Only boxes sufficiently close to a Ground Truth box are evaluated. The higher this value is, the more conservative the metric is regarding choosing False Positives. This will help for datasets which are very crowded but lack annotations.
- IOU threshold (Localization): To calculate Localization score, IOU threshold is used to assign positive and negative boxes.
- Class Exemplar Similarity contrastive threshold: Minimum CEM similarity score for two objects to be considered belonging to the same CEM group.
- Object Score Threshold: Minimum score to consider prediction boxes for matching (to eliminate background boxes)
- Initialized Score Threshold (Tracker): Start a new tracklet on a bounding box with minimum score.


Demo
The paper trained TETer on 2 datasets: BDD100K and TAO. With these two model versions, we opted to test the models in various settings to determine their practical utility. The BDD100K model was tested on city traffic videos given that the BDD100K dataset is primarily focused on detecting classes typical in a cityscape. For the TAO model which is trained on images with a significantly broader number of 1230 classes, we tested the model performance on our custom boat video given that the model performance. Aside from boats, the custom video also contains many other objects such as roads, buildings, and cars to construct a more thorough test of the model.
1. Demo on BDD100K Dataset
The pretrained model on BDD100K Dataset performs relatively well on the test traffic video. Tracking of cars is consistent with few instances of ID switching. However, we do observe that the model could not recover the lost tracklet of certain car instances (e.g tracklet 35 becomes 58 after half a seconds of disappearance). This is probably because the features of this car in the last few frames represent the car’s left side, whereas the car reappears with its right side.

2. Demo on Custom Ship Dataset
Class agnostic tracker tends to be more robust to Object Switching compared to Category Label predictions. It can be seen that with class assignment before association, objects tend to switch classes frequently, whereas for the class agnostic model, despite the class probability changes (color of bounding boxes change), the instance IDs of the tracklets are much more consistent throughout the video sequence.
.gif)
.gif)
3. Limitations
TETer does not work well on low frame rate videos where there are big appearance changes from frame to frame, which may result in CEM or quasi-dense similarity learning not performing well. TETer also suffers from localization errors caused by occlusions, which is a common issue for feature-based trackers like Quasi-Dense Tracker. From the demo of the boat video, the model does not perform well on small-size objects, which can be attributed to the performance and settings of the detector. However, the detector is set to pick up small objects (like cars on the roads), it is expected that many other small objects will be detected, making the tracking more noisy. Overall, if the model is trained on many objects, the performance on the individual classes becomes worse. The tracking performance of the traffic model (trained on 8 classes) is more consistent than the TAO model (trained on > 1000 classes). Thus, if the number of classes of interest is small, consider retraining the model on specific classes to improve tracking performance and reduce model complexity.
Conclusion
Test EveryThing in the Wild paper introduces several new changes to address issues in Multiple Object Tracking for a large number of objects. The proposed tracking algorithm TETer disentangles classification from detection and association. The model is helpful in scenarios where users need to track performance of videos with rare and even unknown classes, videos with many similar classes that might be differentiable or videos with lack of exhaustive annotations. However, if the number of classes to monitor is small, the model should be retrained on data with a smaller number of classes to avoid picking up many False Positive detections. In addition, the usage of Quasi-Dense Tracking means that the model is susceptible to ID switching due to occlusion and appearance changes. In summary, Test EveryThing in the Wild represents a novel push and sign of progress in the task of multiple object detection. However, its impact and practical usage is still limited by the above factors, and we continue to await further improvements to increase industrial viability.
References
Tracking EveryThing in the Wild: https://arxiv.org/abs/2207.12978, https://github.com/SysCV/tet
Quasi-Dense Similarity Learning for Multiple Object Tracking: https://arxiv.org/abs/2006.06664
Simple Online and Realtime Tracking with a Deep Association Metric: https://arxiv.org/abs/1703.07402
https://github.com/mikel-brostrom/yolov8_tracking
ByteTrack: https://github.com/ifzhang/ByteTrack
.png)
.png)
