.png)


Introduction
As the wave of machine learning continues to take over research and industry, use cases in computer vision are becoming increasingly prevalent. Computer vision has demonstrated tremendous potential in numerous applications including but certainly not limited to object tracking, insurance, and defect detection.
Recently, students from Singapore Management University used computer vision to create exciting and innovative computer vision projects without a single line of code through the help of Datature’s Nexus platform. We showcase three particularly promising applications below.
Use Case 1: ClaimsVision
Combating Opportunistic Automotive Insurance Fraud through Computer Vision
What is Car Insurance Fraud?
Motor insurance fraud occurs when vehicle damage claims are fraudulently inflated or manufactured for the purpose. According to the General Insurance Association of Singapore (GIA), about $140 million was wasted in 2016 paying and investigating fraudulent and inflated claims.
Problem Statement
ClaimsVision aims to identify opportunistic fraud claims through the assistance of computer vision. Applying computer vision enables greater scalability and saves manpower costs by performing an automated initial inspection of claims that can help to identify anomalies.
Data Acquisition
The data was sourced from these datasets (Kaggle, Roboflow, Peltarion, and GitHub). Annotations were tagged by damage type, color, and location. The dataset and annotations (CSV 4 corner bounding box format) were then uploaded onto the Nexus platform.
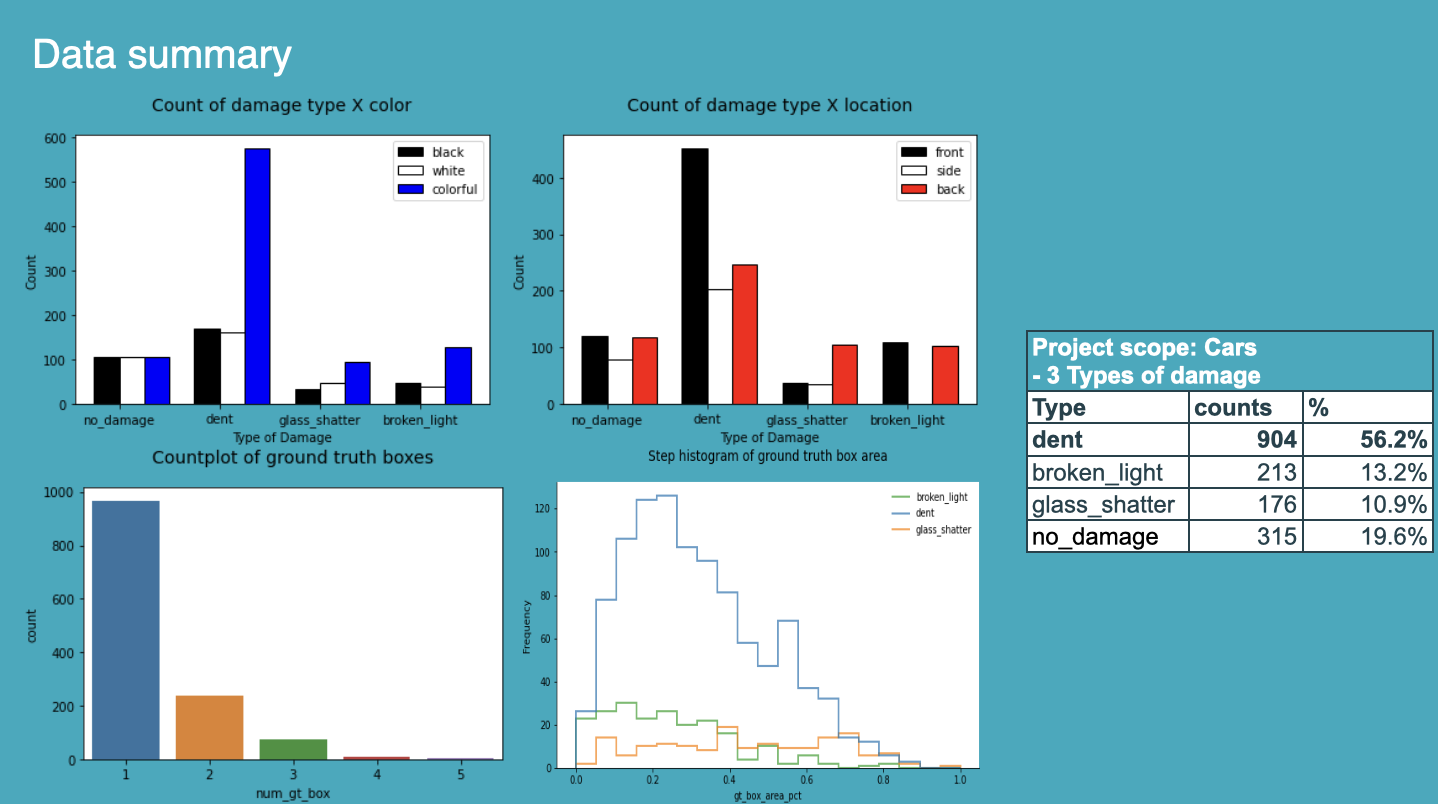
The entire process of training an object detection model was within the Datature platform. They were trained to measure 3 types of damage - Dent, Glass Shatter, and Broken Light. Through small initial trainings, they determined the ideal setup was to use FasterRCNN InceptionV2 640x640 with these augmentations and dataset setup as follows:
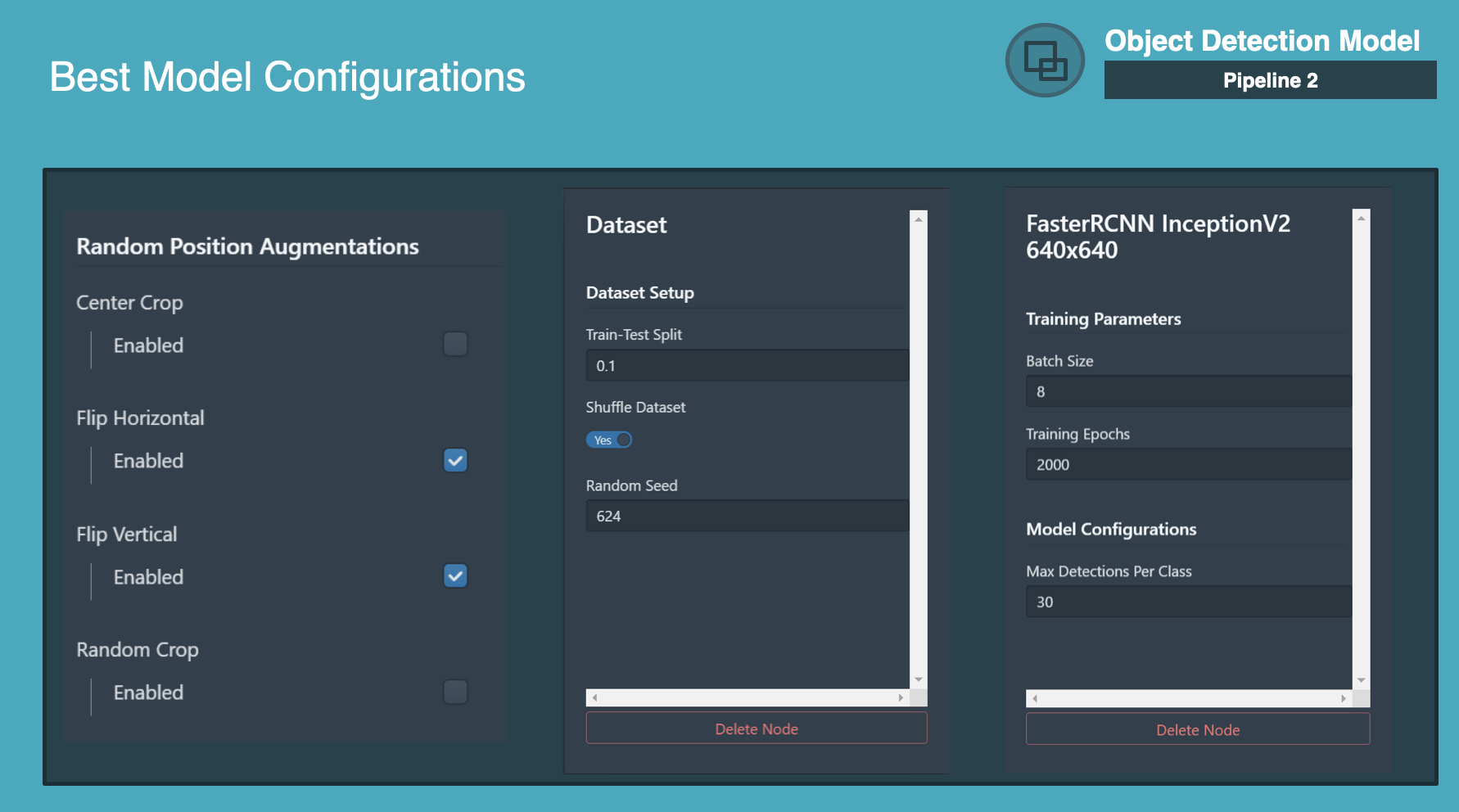
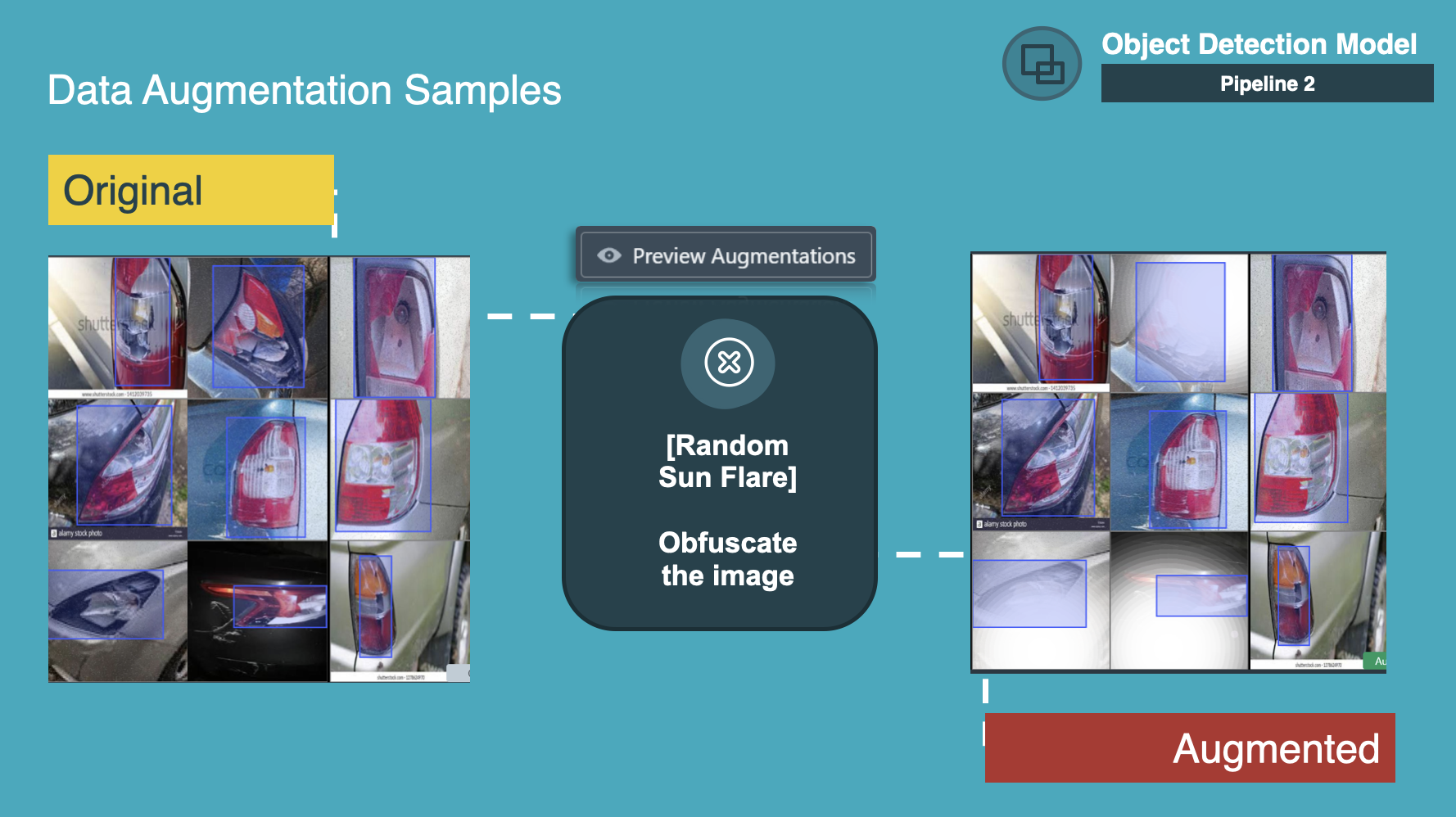
Additionally, we used these artificial augmentations to increase model robustness.
Random Position Augmentations keep the size of the data input more similar but also augmenting the dataset by shifting or removing certain details in the visual data such that the model isn't reliant on specific features.
Flip Horizontal, Flip Vertical, and Shift Scale Rotate were used to create artificial variety to replicate the possibility of users taking images of the damage from different angles. This will make the model more robust to these possible transformations.

Color Space Augmentations will alter pixel values such that the color representation changes. This augmentation technique is used so that the model is not dependent on the color space for making predictions. Oftentimes, data-collecting instruments will not be identical and the lighting in which the visual data is collected may not be the same, so colors can be drastically different in test or inference environments even if the main features in the data remain the same.
Random Sun Flare applies a random number of sun flares within a certain area from a random angle that obfuscates the images so that we could mimic actual sunlight that would happen in daylight conditions.
Training Results
With our choice of methodologies - overfitting on a small dataset & choosing models with promising results to train on a full dataset, and adjusting the different kinds of augmentation techniques. We concluded that FasterRCNN- Inception_v2 640x640 gave the best results (0.31 Val mAP); we used 2x NVIDIA-TESLA-P100 and the total training time took 76 minutes. We felt that while the RetinaNet and YOLO models performed relatively well, the predictive outputs were oversaturated with predictions.
Technical and Business Considerations
In order for the model to be deployed effectively from a business perspective, it is essential that the model is routinely monitored for both concept drift and data drift & to evaluate its business metrics.
To manage the issues of concept drift, we can evaluate the properties of P(Y|X), monitoring for drift by tracking statistics like F1/mAP periodically on submissions. We also delve into data drift and evaluate the properties of P(X) changes, and track the data properties after.
From a possible business metric and heuristics perspective, considerations such as time savings and ability to capture fraud are measured. Our simulations show that from a time savings perspective, automated predictions can reduce time to verify and match different damage types if the prediction is able to accurately identify damage. In scenarios where the model is unable to detect damage or identifies it inaccurately, it simply goes on for normal verification which would be unchanged from normal processes. In evaluating the ability to capture fraud, the percentage of necessary checks would increase with increased fraud, but caught fraud would remain stable. Overall, simulations suggest that automated fraud detection can only enhance and reduce time needed in the pipeline by reducing the number of checks needed.
With all our preparations in mind, such as redeploying the new model, encouraging adoption, tracking the model results, and using the aforementioned data submitted to finetune results - a self-sustaining circular ecosystem is developed and the possibility of mass adoption is likely.
Use Case 2: You Only Edit Once (YOEO)
An AI-Powered Video Editing Tool for Leisure Divers
How Does One Produce Amazing Diving Videos?
As an amateur diver, one might expect to see a plethora of colorful fish and brimming seabeds in your diving videos. In reality, the majority of such videos have only a few of these brief moments.
Problem Statement
We seek to automate the process of evaluating these valuable moments by determining the total number of objects or the area covered by objects through object detection in order to compile exciting diving video footage.
We came up with a Streamlit web application solution built on top of a YOLO model called ‘You Only Edit Once (YOEO). This solution consists of 3 key elements:
- Firstly, it facilitates video truncation through object detection - a type of hands-off video editing which allows AI to truncate your video so that every frame includes objects of interest.
- Secondly, it allows you to stitch your truncated video with any audio of your choice.
- Thirdly, it uses image extraction from your curated video and beautify them to generate desktop wallpapers.
Data Acquisition
For data collection and processing, we extracted sample frames from our diving videos and annotated them on the Datature platform. Our dataset consists of 76 videos (16 from Youtube, and 60 from our personal files) which we then extracted into 477 images. We then separated them into 5 different classes: sharks, rays, turtles, corals, and fishes and annotated them using bounding boxes.
Artificial augmentations, also supported on Datature, were used to create more realistic variations in the dataset.
For positional augmentations, Shift Scale Rotate was used to accommodate fishes or the camera capturing footage from different angles, areas, and levels of zoom.
For color space augmentations, Median Blur, Hue Value Saturation, and Grayscale were used. These augmentations were used to account for more variations in camera quality, lighting, and moving objects being captured at test time. By including these augmentations, we allow the model to train on a wider range of data.

Training Results
For model finetuning, we fine-tuned both our YOLOV4 and YOLOX models on the Datature platform. Based on several metrics, we concluded that YOLOX Medium 640x640 was the best model for our use case. Using mean average precision (mAP) as our main metric, we determined that the best mAP score was at epochs 2500 and 3000 with an mAP of 0.02. The corresponding results were achieved using batch size of 8, 3000 epochs, and 10 detections per class.
The model performance was limited by several factors. In some cases, we observed misclassification, loose bounding boxes, and the inability to recognize more than a few individual fishes. For a more thorough technical analysis, we also used YOLOX’s nano models for inferencing for comparison and better understanding.
Post-Processing Methods
With our models trained, we jump into post-processing so that we could develop our video, stitch up some audio, and integrate image enhancement algorithms if need be.
Video Trimming and Re-Stitching
With the large amount of video footage that we have gathered, video trimming and re-stitching would be an essential process. To facilitate the automatic selection of scenic frames, two assumptions had to be made. The first assumption is that a frame is scenic if a good portion of the frame contains objects of interest. We decided to take the ratio of the sum of the total area of all objects with the area of the frame and ascertain if this exceeds the desired threshold. If the frame exceeds the desired threshold, we will keep the image. Likewise, if it doesn’t we will discard it.
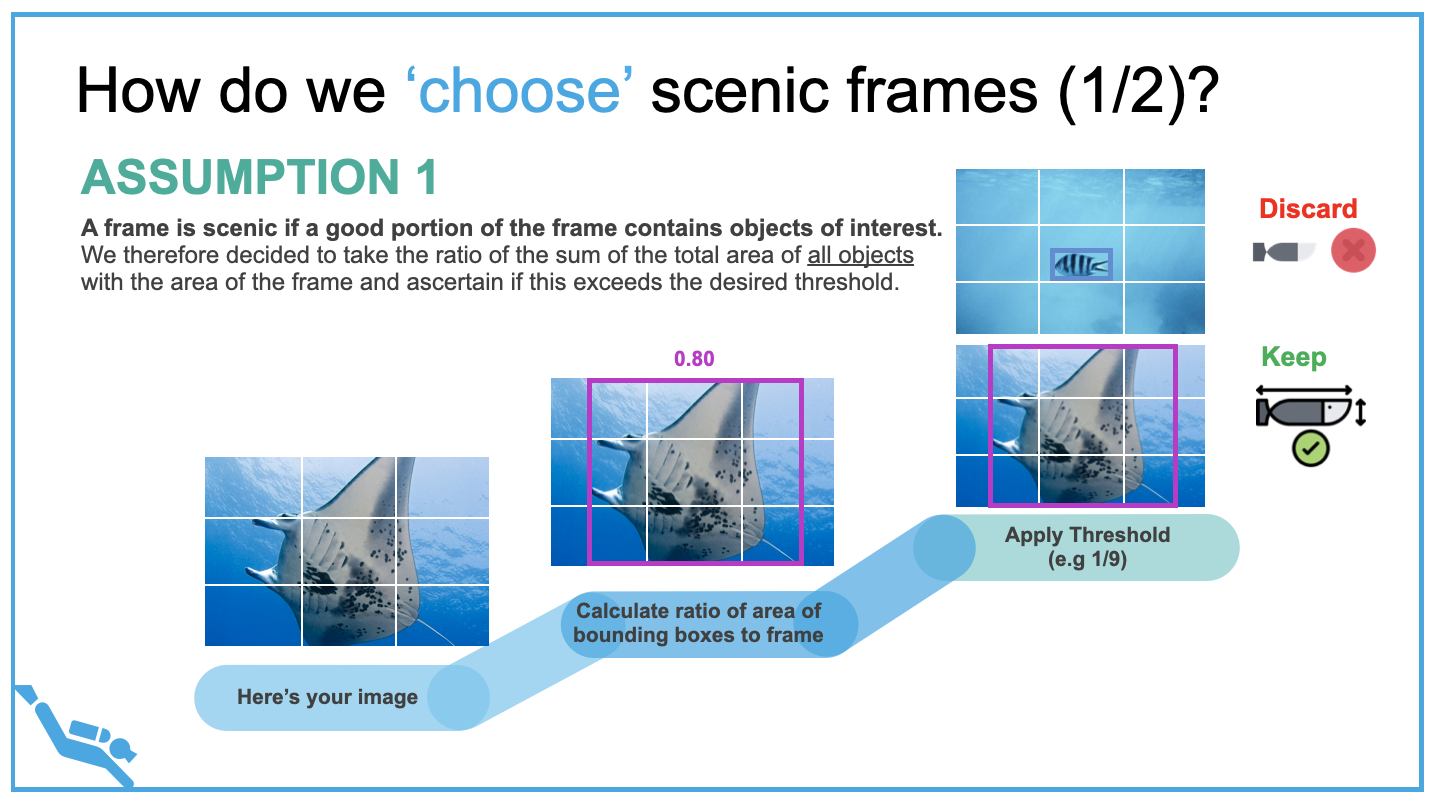
The second assumption that we made was that a frame is scenic if there are many objects of interest in the frame. We decided to count the number of each type of object detected and weigh it with an empirical score; then combined it together with the area scores. Sharks, turtles, and manta rays were given higher weighted count scores due to their rarity.
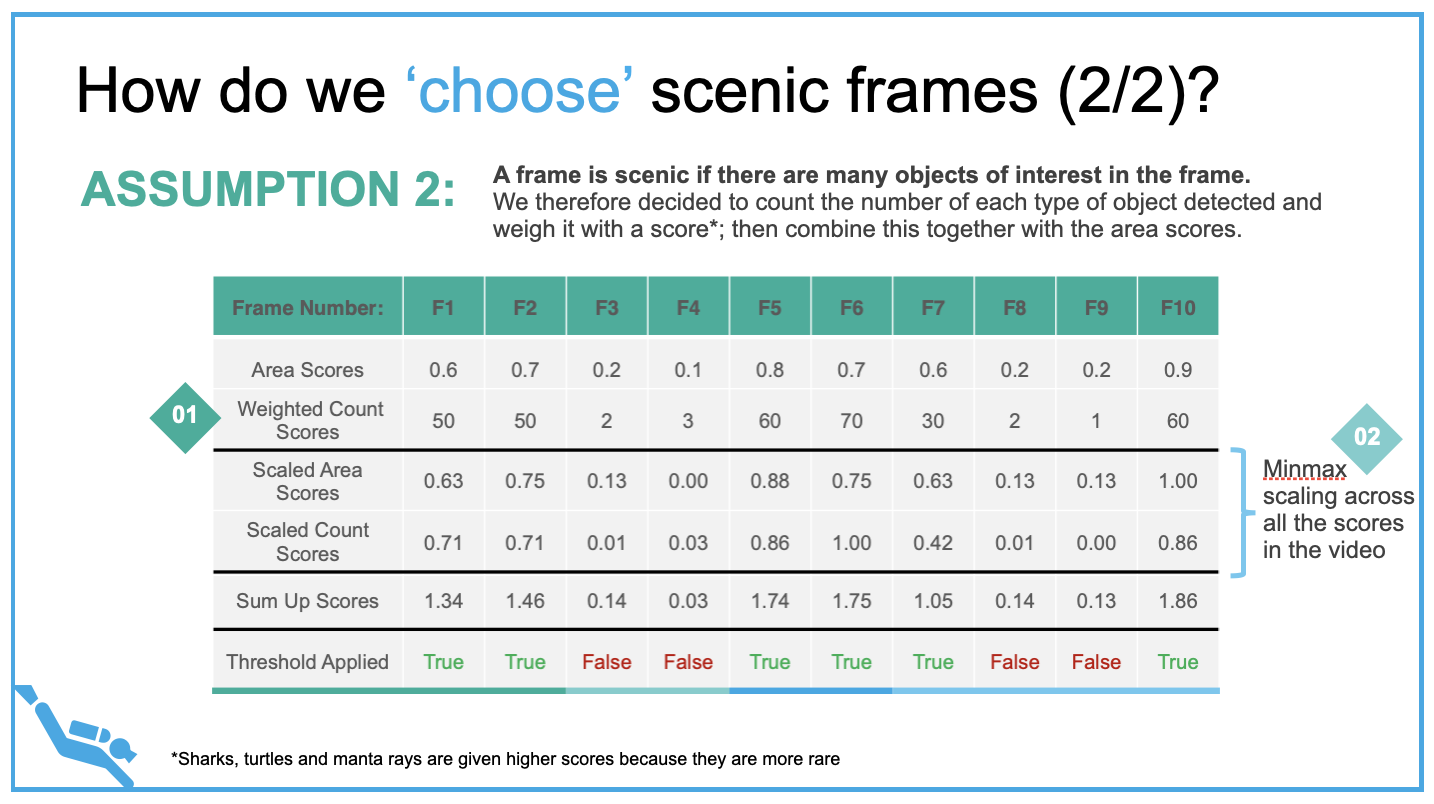
After determining which frames are scenic, relevant frames are stitched together with the frame per second rate set to be equivalent to the initial input video. Users can then select their own choice of audio (mp3, mp4, etc) or to use a dive video friendly audio default track. Audio tracks are processed to ensure every part in the final video has audio, processing is necessary because the duration of the stitched video and the audio track differs.
Image Enhancements
Our algorithm filters out only the best frames based on frame scores, and we are able to enhance these frames by either increasing the amount of red light and reducing the amount of blue light in the picture or adjusting the brightness and sharpness automatically. To add the icing on the cake, our algorithm is also able to add an Instagram filter of your choice on top of the enhanced frames.

Challenges and Future Considerations
We felt that when there was a school of fish or a forest of coral, annotating was a very difficult process. Additionally, we also felt that humans get misclassified a lot and we should have better trained our model to train on more images containing humans. We also thought that there was a class imbalance without a dataset, there were just so much more fish and coral than sharks, turtles, and manta rays. Lastly, “beautiful” images are subjective, ultimately thresholds for brightness and sharpening levels had to be manually tuned. We settled on a blurriness threshold (variance of Laplacian) of 50, and an acceptable perceived threshold of brightness level to be within 130-145 - this range was determined after testing on many of our own photos and diving videos.
With our current proposed solution, we could auto-trim a video to only show interesting frames with objects of interest, accompanied by music. However, what we envisioned in the future was for our solution to automatically record diving snippets when interesting frames are detected.
In terms of images, our current solution could beautify top frames from the video footage, and allow users to instantly use them as wallpapers or share them on social media. In the future, we envision that our solution could automatically snap photos of desired classes when they appeared in the frame.
Interested to give YOEO a try? Download our YOEO Streamlit app here. To beautiful footage on your next diving adventure!
Use Case 3: PODOR
Pothole Detection Online Reporter
Singapore is a small land-scarce country with more than 9,000 lane-kilometers of road. This constitutes 12% of the entire country. In January 2021, the number of potholes detected in Singapore was 1,400 which is double the monthly average of the previous year.
A pothole is a depression in a road surface, usually asphalt pavement, where traffic has removed broken pieces of pavement. The annual total rainfall for 2021 is at 3167.7mm which is 25% above the long-term annual average of 2534.3mm over the past 30 years. As the main cause of potholes’ formation is due to excessive rainfall, the increasing trend in rainfall is a concerning factor.
Existing methods use costly technology such as LiDAR to detect potholes. By using computer vision technology and tapping on existing infrastructures, costs can be greatly reduced while also increasing efficiency and productivity to fix existing potholes.
Problem Statement
PODOR aims to identify potholes on roads from videos and images taken from existing CCTV systems such that maintenance can be expedited and potential accidents can be prevented.
Using computer vision to identify potholes from images, will enable the relevant parties to expedite repairs and deploy manpower based on importance. The key benefits of using computer vision are the ability to work as a standalone solution, cost-reduction and efficiency improvement, and the ability to have a high accuracy when dealing with images if it’s trained with good data.
Proposed Solution
By framing the problem as a semantic segmentation task, the proposed pipeline will be as such. An image of the pavement is taken and sent to the model. Once the model has the images, it will output the number of potholes, and classify the severity based on the number and size of potholes detected. This information which contains the number of potholes, severity and geographical location is then sent to the dashboard. The control center will proceed to read from the dashboard and prioritize their response to a given location based on the severity.
Data Acquisition
The training dataset of more than 500 pothole images was obtained from both Google & Kaggle respectively and labeled manually with masks over each of the potholes. The test dataset consisted of real-time images taken in Singapore.
Training Setup
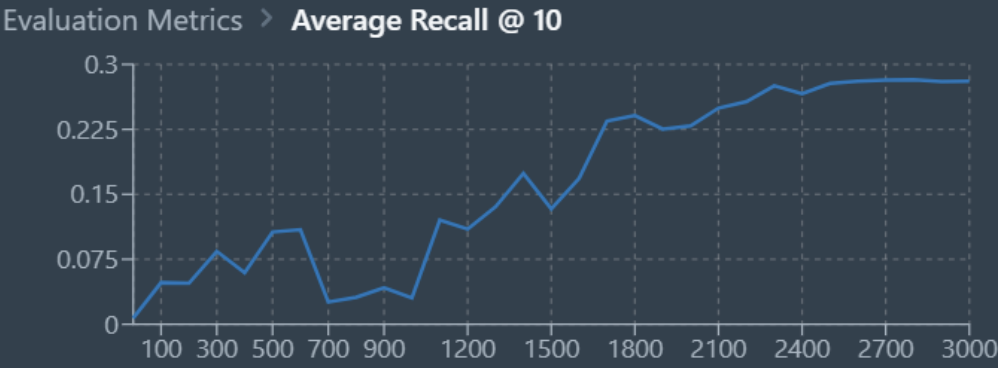
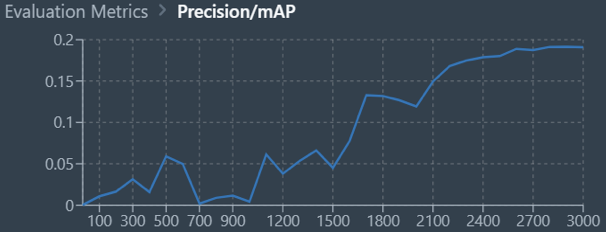
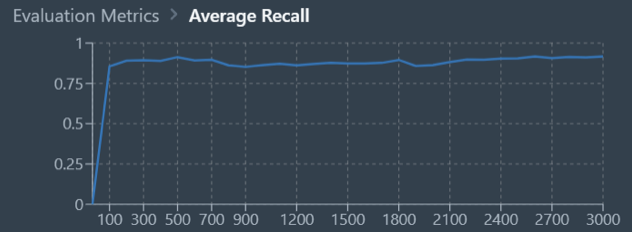
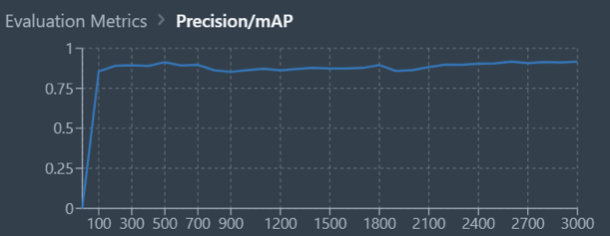
The model architectures we experimented with were MaskRCNN and DeeplabV3 with ResNet101 as the backbone. These models were trained on Datature’s Nexus platform. The primary metrics we used to evaluate training performance were recall and precision/mAP, with the goal of measuring how accurate the predictions were compared to true labels and positioning, and thus facilitating correct prioritization of pothole repair schedules.
To improve the robustness of our training dataset, we used artificial augmentations from the Datature workflow.
Of the positional augmentations, Flip Horizontal and Flip Vertical were used, to ensure that the model was robust to positioning and perspective.
For the color space augmentations, we used Gaussian Noise, Glass Blur, Motion Blur, and Random Rain. This is to account for the way in which the images are captured, as quality can’t be guaranteed, so adding these effects will help the model be better at segmentation despite variations in image quality.

Training Results
With the MaskRCNN and DeeplabV3 models, we achieved the following results with 3000 epochs of training. As the graphs below indicate, DeeplabV3 achieved higher values of recall and precision far more rapidly and overall when compared to MaskRCNN. This could be due to the size of the MaskRCNN model being overly large as compared to training dataset and mask complexity. Overall, DeeplabV3 was able to achieve recall and precision above 0.8 as compared to MaskRCNN which achieved average recall and precision slightly below 0.3.
MaskRCNN:
DeeplabV3:
System Architecture with Downstream Integration
The main pipeline can be hosted with a Flask application, where a UI provides the user the ability to upload image data collected from transport authority sources like CCTV cameras. On the Datature side, images can be annotated on the platform and training and retraining of the model can be done on that end. Then, the model can be hosted as an inference API either locally or on cloud. When images are called for inference, the Flask app will make a request to the model hosted API which will return the masked image, pothole severity, and pothole score.
Pothole severity is calculated based on the size of the bounding box surrounding each pothole. We then take the largest pothole in the image and compare it to a threshold. If the largest pothole’s area is large enough, then it can be considered a certain level of severity. These thresholds are customizable to accommodate whether frequency of potholes or severity of potholes should be prioritized in the queue.

Future Improvements
We hope to train the model with more data, and implement continuous learning with new images as we receive them. Additionally, analyzing potholes from video footage could be a manageable goal to reach. Including pothole depth as an extra dimension in severity analysis would increase the detail. Model architecture could also be further finetuned for this scenario given more experimentation. Finally, the overall app could be improved, and the application could be applied to many other public traffic service domains.
I hope that you found the above use-cases interesting to learn about and the source of inspiration for your next computer vision project. If you have any new projects in mind or want to replicate the results of the projects above, feel free to check out Datature’s Nexus platform as an accessible tool to hold your entire computer vision pipeline, from data storage and annotation to model deployment!
References
San Ren Yi, C., Wei Lun, K., Si Xian, L., Li Lin, T., & Tiak Leng, T. (2022). ClaimsVision: Combating Opportunistic Automative Insurance Fraud through Computer Vision.
Xinyi, H., Te Yang, L., Zihao, L., Hsien Yong, L., & Licheng, Y. (2022). You Only Edit Once: An AI-Powered Video Editing Tool for Leisure Divers.
Baljit Singh, P. S., Haresh Lalla, P., Tan Zong Yang, I., Teck Sheng, C., & Jun Jie, K. (2022). PODOR: Pothole Detection Online Reporter.


.jpg)